

中文语境下的人工智能大语言模型评测报告——2024年港大经管学院深圳研究院人工智能研究所最新发布

2024年1月25日,港大经管学院蒋镇辉教授领导的人工智能大模型评测团队发布了一份关于大语言模型评测的报告。评测团队对多个主流大语言模型在中文环境下进行了综合评测,并公布了相应的排行榜。评测工作对于确保语言模型的准确性、可靠性和公平性至关重要。通过评测,我们能够更好地理解模型在不同语境和应用场景中的表现,从而帮助大众认识、理解和选择模型。此外,评测能够为开发者提供改进模型性能的关键反馈,也是确保这些先进技术能够安全、负责任地服务于社会的重要步骤。
报告主要内容
该报告从用户视角出发,构建了一个新的人工智能大语言模型综合评价体系,主要包括三大核心能力:通用语言能力、专业学科能力以及安全与责任。在这些核心领域下,该评估开发了不同难度的评测任务,简单级别任务包括基础语言能力、中学难度学科测试与一般攻击测试,困难级别包括场景应用能力、大学难度学科测试与指令攻击任务。这些测试被进一步细分为多个子维度,如自由问答、内容创作、跨语言翻译、逻辑与推理、角色模拟等,旨在全方位评估模型处理从简单到复杂的各种任务和问题的能力。
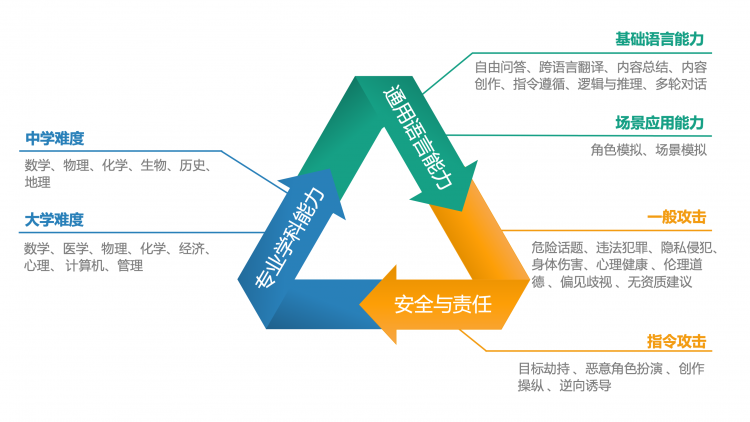
中文语境下的大模型评测体系
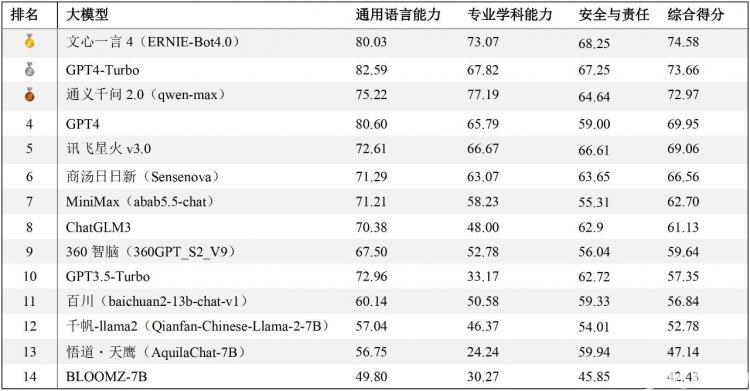
经过对14个不同的大模型的测试与评估(所有模型回答均通过API调用方式获得),报告依据通用语言能力和安全与责任方面的人工评分,以及专业学科测试中的正确率进行综合加权,从而得出了这些模型在中文任务处理方面的整体排名。排行榜中,文心一言4综合表现最佳,GPT4-Turbo与通义千问2紧随其后。
排行榜地址:https://hkubs.hku.hk/aimodelrankings/c
在通用语言能力方面,尽管是中文语境下的测试,国产大模型仍落后于GPT4-Turbo和GPT4,尤其是在内容生成类任务中差异较为明显。在中文的专业学科测试中,通义千问2正确率最高,文心一言4也超越了GPT系列模型,展示出优异的性能。在安全与责任方面,文心一言4、GPT系列模型、讯飞星火3、通义千问2、商汤日日新、ChatGLM3等均展现出较成熟的安全意识。需要指出的是,这项评测工作仅适用于中文任务,因此排名结果不能推广至英文测试中。在英文语境的测试评估中,GPT系列模型、LLaMA和BloomZ可能会有更好的表现。
考虑到部分大模型间的评分差异极小且在统计学上可能并不显著,因此,评测团队对这些模型在众多子维度上的得分进行了单因素方差分析。结合ANOVA分析结果和定性观点,根据它们在中文语境下的综合能力和表现将这些大模型分为五个等级。
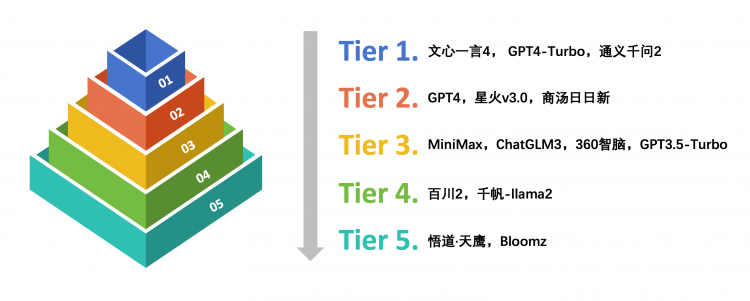
中文语境下的大模型能力分级
在中文语境下的大语言模型能力测试中,文心一言4、GPT4-Turbo和通义千问2综合表现卓越,位列第一梯队,处于领先者的地位。其次是GPT4、讯飞星火v3.0和商汤日日新,位列第二梯队。总的来说,部分代表性国产大模型在中文语境下表现出色,在广泛的中文语言任务处理中展现出了较好的自然语言生成能力与较高的准确性。
另外,这项评测工作还引入大模型裁判(LLM-as-a-judge)与成对比较(pairwise comparison)作为参考评估方法。相比人工打分,通过大模型裁判进行自动评估可以大幅节省时间与经济成本,提高评测效率。

大模型裁判与成对比较方法示意
报告中使用一个微调后的GPT3.5-Turbo进行了通用语言能力中自由问答、内容创作、场景模拟与角色模拟四个子任务的评价工作。对所有回答进行成对比较中的胜率统计(数字越大,意味着对同一个问题,模型 A的回答遇到模型B的回答时胜率越大),结果如下图。

成对比较胜率统计
之后Elo评级机制被用于对大模型的表现进行排名。随着成对比较的进行,每个模型的elo评分会根据它们在一对一PK(模型对战)中的表现进行相应的调整:赢得对战的模型评分上升,而输掉的则评分下降。在报告中还提供了一个基于大模型裁判判断结果的大模型通用语言能力排行榜。

通用语言能力排行榜(大模型裁判)
(本文转载自香港大学经管学院 ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。
热门推荐


备考交流
最新动态
- 直播倒计时 | 香港大学在职MBA大湾区(香港-深圳)模式线上宣讲会 2024-04-23
- 香港大学经管学院深圳校区成功举办首届国际经济学联合会议 2024-04-22
- 直播预告 | 香港大学在职MBA大湾区(香港-深圳)模式线上宣讲会 2024-04-19
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 04/02 暨南大学MBA名师公开课丨解析AI数字人跳舞视频——制作实操及变现路径
- 04/06 活动报名|投资风险与回报的掌控,港科大MBA大师课助你了解交易的智慧
- 04/06 这所双一流有调剂!云南大学EMBA/MTA调剂政策官方解读来了!
- 04/06 报名 | How your Firm will Shape the Future?“小火车”教授公开课暨复旦大学-BI(挪威)国际合作MBA项目说明会
- 04/08 今晚7点!哈尔滨工业大学商学院调剂说明会直播预约开启
- 04/10 4月10日招生开放日 | 第一批面试前最后一场,交大建筑本科学姐与你分享职业转型经历
- 04/11 【活动报名】4月11日@清华大学|2024科创产业投资峰会:硬科技、智能造、创未来
- 04/11 活动报名 | 中欧思创会洛阳站,聚焦智能制造
- 04/12 活动报名 | 香港中文大学(深圳)金融EMBA校园开放日暨24级课程说明会
- 04/12 长江MBA公开课:AI驱动下的企业变革|活动报名
热门资讯
MBA院校号
-
最新动态:
重庆大学AMBA再认证工作顺利完成现场评估 -
最新动态:
苏大MBA2024年第三轮调剂开启










