

北大光华涂云东:大数据时代,如何应对经济和金融数据的不稳定性?|学术光华
数据采集和存贮技术的飞跃发展,孕育了众多领域的大数据。大数据出现在包括金融、经济、管理等各种领域,为计量经济学的发展带来了前所未有的机遇和挑战。在过去的二十年间,大型因子模型被广泛地用来分析高维数据。经济学和金融学中的高维数据集通常以较大的横截面维度N和较长的时间维度T为特征。而高维因子模型可以用少数几个潜在的因子来捕捉到高维变量中的大部分信息,因此得到了经管学科的广泛关注。
关于高维因子模型的理论研究和数据分析经常是基于线性的假设。然而实际的宏观经济运作、企业经营管理经常受到国家政策、新技术革新、全球金融危机等的影响,因此其数据结构经常发生变化。另外,考虑到大数据观测时间长,样本容量大的特点,经济学模型很容易具有结构不稳定性和非线性的特征。因此,结构不稳定性的分析在经济数据,特别是高维时间序列数据上起到至关重要的作用。忽略高维因子模型中出现的结构不稳定性,将会导致错误的推断和预测。
北京大学光华管理学院商务统计与经济计量系涂云东教授在因子模型及其结构不稳定性领域进行了深入研究。由涂云东教授与其指导的博士生马辰辰共同撰写的两篇论文“Group Fused Lasso for large factor model with structural breaks”和“Shrinkage Estimation of Multiple Threshold Factor Models”先后发表在计量经济学国际顶级期刊Journal of Econometrics(《计量经济学杂志》)上。两篇论文针对经济和金融数据的结构不稳定性,在高维因子模型的框架下,提出了关于结构变点和门限效应参数的全新估计方法,力求提升参数估计的准确性和计算效率,进而展现计量经济学和统计学的方法在分析经济问题中的广泛应用。

Part.1高维因子模型及其结构不稳定性
因子模型采用少数因子即可捕捉到高维观测变量中的大部分信息,因此成为分析高维时间序列数据的一个重要的工具。尤其是在目前的大数据时代,因子模型受到了越来越多的关注,其模型表达如下:
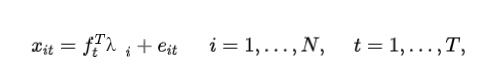
其中xit是我们观测到的高维时间序列数据,ft是潜在的因子,λi是相应的因子载荷,eit是残差项。自从Stock和Watson(2002)以及Bai和Ng(2002)的有影响力的研究以来,计量经济学领域和统计学界对高维因子模型中推断的研究兴趣激增,最新发展包括Bai和Li(2016)、Chen等人(2021)等。
在现有的文献里,对因子模型理论研究和数据分析大多都是基于线性模型假设(Bai 和 Ng,2002;Bai 和 Li,2012;Bai 和 Liao,2016),也就是说这里的因子载荷λi是一个不随时间变化的常数。然而,实际的经济环境经常会受到科技突破、政策发布、金融危机等的影响,因此其数据结构经常发生变化,这使得上述的线性因子模型的假设在实际的数据分析中变得十分脆弱。考虑到大数据观测时间长,样本容量大,因子模型可能具有结构不稳定性和非线性特征。因此,为了解决真实复杂大数据中的因子降维,带有结构性变化的大型因子模型和非线性因子模型成为近年来研究的热点。
Part.2高维因子模型中的结构变点估计
Stock 和 Watson(2002, 2009)研究得出结论,当因子载荷出现小的(局部收敛到0)突变时,通过主成分分析估计的因子同样具有一致性。但是Breitung 和 Eickmeier(2011)发现如果忽视因子载荷中的突变,将可能会导致识别出更多因子的错误结果。于是学者针对因子模型中的结构变点陆续提出了不同的检验和估计的方法(Chen et al.,2014;Han 和 Inoue,2015;Su 和 Wang,2017;Ma 和 Su,2018;Baltagi et al.,2017,2020)。大部分的研究仅仅关注于因子载荷中只存在一个变点的情况。但是在大数据时代,研究者越来越致力于研究更高维的数据集,这些数据会包含数百个变量,并包含极大的时间跨度,部分甚至所有的变量都可能在采样周期发生超过一个突变。但是目前关于多个变点的研究中,通常会存在调节参数或待估参数过多的问题,从而使得方法过于复杂,理论研究难度较大。所以当因子模型中存在多个结构性变点时,简单易行的估计和检验方法亟待提出。
涂云东教授等2023年发表的论文很好地解决了这一问题 (Ma 和 Tu,2023a)。他们考虑在大型因子模型中,因子载荷中存在的多个变点的估计问题。也就是说因子载荷λi在时间维度上被划分成多个时段:
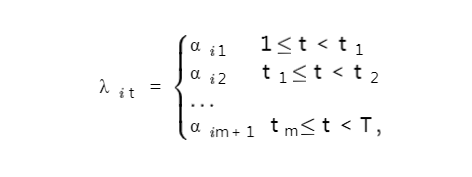
这里结构变点为t1, ... ,tm,αi1, ... ,αim+1,为因子载荷λi在不同时段上的取值,相邻两段上的因子载荷互不相同。
该论文拓展了Chen等人(2014)关于单一变点的结果,将因子载荷中结构变点的识别问题转化为因子回归方程中系数的结构变点估计,然后提出了一种基于group Lasso 的估计方法来识别变点日期。这里考虑的因子模型允许变点的数量和日期都未知。此外,这篇论文允许因子个数随着时间的变化而变化,也就是说变点前后可能有新的因子出现,也可能有旧的因子消失。估计方法可以通过简单的两个步骤实现:首先,忽略变点,用主成分方法估计因子,并用Bai 和 Ng(2002)提出的信息准则估计因子的数量。其次,用其中的一个估计的因子(例如,拥有最大特征值的因子)作为因变量,其余的因子作为自变量进行线性回归。将因子载荷中突变点的估计转换为线性回归方程的突变点的估计问题。因此可以用Group Fused Lasso的方法(Qian 和 Su, 2016)将回归方程中所有突变点同时估计出来。
该论文在理论上建立了变点估计量的一致性并推导了其渐进分布。同时,数值模拟表明,与现有方法的结果进行比较,该方法在大幅度提升估计效率的同时得到相对较小的估计误差。最后,论文将该方法运用到美国宏观经济的数据进行实证研究。这个数据集包含108个美国月度的宏观经济数据集,包括实际经济活动指标、价格、利率、货币和信贷总量、股票价格和汇率等变量。其时间跨度从1959年1月份到2006年12月份。通过建模和分析,该研究识别出5个变点,分别是1979年9月、1983年9月、1990年11月、1995年7月和2000年5月。这些变点对应于伊朗革命、大缓和时期、劳动生产率的提升和经济衰退等。
Part.3高维因子模型的多门限估计
考虑高维因子模型结构不稳定性的另外一种模型是最近被频繁研究的门限因子模型。门限因子模型和带有多变点的因子模型相似却又不同。一个主要的区别在于,变点模型的变化是发生在时间维度上的,而门限模型则是允许因子载荷根据门限变量的大小发生变化。所以,门限因子模型更适合于描述一些历史重复的现象。在文献中,Ng和Wright(2013)模拟了一个符合高维门限因子模型的数据,以研究非线性对商业周期动态的影响。Massacci(2017)和Liu和Chen(2020)考虑了高维时间序列的门限因子模型,其中假设时间序列在两种状态之间切换。Wu(2021)进一步将Massacci(2017)的分析拓展到一个带有多个门限的因子模型中。门限因子模型不仅为降维提供了一个强大的工具,还增强了建模的灵活性,提供了一个更易于解释和预测的框架,可以轻松捕捉潜在的非线性。
高维多门限因子模型中载荷的建模具体为:

这里的zt是可观测的门限变量,根据其取值大小因子模型被分成不同的区制。γ1, ... ,γm是待估的门限值。αi1, ... ,αim+1为因子载荷λi在不同区制上的取值,且相邻区制上的取值不同。
涂云东教授及其合作者2023年的另一篇文章对这种门限驱动的结构不稳定性进行了详细地阐述,并提供了一种创新的估计方法(Ma和Tu, 2023b)。仅仅借助于重排、主成分分析和压缩估计,该方法能够将门限的个数和参数值一致地估计出来,并且在操作上简单易实施,计算上也能大大提高效率。估计方法包含两个主要的步骤。第一,文章通过将可观测的时间序列xt按照门限变量zt的大小进行重排,将多门限因子模型转化为多变点因子模型;第二步运用涂云东教授提出的因子模型变点估计方法 (Ma and Tu,2023a)识别变点,继而根据变点的位置找到相应门限变量的值来对门限值进行估计。具体的方法介绍参见Ma和Tu(2023b)。
理论方面,他们证明了门限数量和估计值的一致性。蒙特卡洛模拟表明该方法在有限样本中估计得很好。进而,文章将提出的方法运用到分析美国金融市场数据的分析中。数据跨度为1985年1月到2011年12月,共有324个月度观测值。这里使用的门限变量zt是Baker等人在2016年提出的关于经济政策不确定性的衡量指标。正如Baker等人所说,经济政策不确定性指数与国防、医疗保健、金融和基础设施建设等政策敏感部门的股价波动和就业有关。当政策不确定性不同时,金融市场的行为也相应有所不同,因此文章中通过提出的多门限因子模型来研究经济政策不确定性是如何影响金融市场,计算了多元非线性动态系统中的连通性(connectedness) (Massacci, 2017),评估了每个区制中因子的重要性,最后也对比了门限因子模型和结构变点因子模型的有效性。

该表格截取自涂云东教授文章中(Table 5, Ma 和 Tu, 2023b)。从该表可以看出,随着经济政策不确定性的增加,连通性逐渐增加,这说明经济变量之间的相关性变强,可能会增加系统风险水平。这一发现有利于风险的衡量和管理。因子的个数在不同区制中也有所不同。涂云东教授在文章中也分析了每段中因子所代表的具体含义,发现与市场风险相关的变量在金融市场中发挥着关键作用。尤其是在第二个区制中,7个因子中有5个与风险有关。此外,随着经济政策不确定性的增加,一些行业投资组合,如食品和煤炭行业,在金融市场中占据着越来越重要的地位。

涂云东,北京大学光华管理学院商务统计与经济计量系和北京大学统计科学中心联席教授,研究员。入选首批“日出东方”北大光华青年人才,教育部“长江学者奖励计划”青年长江学者,两次获评北京大学优秀博士学位论文指导教师。2012年获美国加州大学河滨分校经济学博士学位,同年6月加入北大光华。三十余篇学术论文发表在Journal of Econometrics, Econometric Reviews , Journal of Business and Economic Statistics,Oxford Bulletin of Economics and Statistics ,Statistica Sinica ,Journal of Empirical Finance,Computational Statistics and Data Analysis等国际一流专业杂志。理论研究领域涵盖非参数/半参数计量经济模型,模型选择和模型平均,网络数据建模,金融计量,信息计量经济学,模型设定检验等;应用研究包含宏观经济预测,价格指数建模,网络数据分析,股票市场预测,新冠肺炎预测等。
(本文转载自北京大学光华管理学院 ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。
热门推荐


备考交流
最新动态
- 北京大学光华管理学院与雄安新区党政办公室签署学生思政实践合作协议 师生党员赴雄安新区开展主题学习 2024-04-29
- 河南漯河:“大食物观”的领跑者| 光华MBA共同富裕讲堂 2024-04-26
- 浙江常山:共同富裕,一切为了U | 光华MBA共同富裕讲堂 2024-04-25
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 05/04 报名 | “中国经济变局下的企业风险管理”复旦大学李若山教授公开课暨联合宣讲会
- 05/08 集赞赢取精美礼品 | 面试诀窍、备考经历、海外交换,报名5月8日面试圆桌派,用10个问题揭秘三位高分学长的备考秘籍!
- 05/12 招生工作|浙工大校园开放日暨MBA、MEM项目宣讲会通知
- 05/12 「复旦大学 EMBA 项目」与「复旦-台大 EMBA 项目」介绍会 | 活动预告
- 05/17 限时抢位!长江商学院MBA项目5月北京体验课
- 05/18 5月18日 | 全国首场中国商学院招生巡展暨2025招生政策发布会(北京站)重磅来袭!
- 05/18 5月18日 | 北京体育大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 中国矿业大学(北京)邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 北京师范大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 天津大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)










