

上财信管 | 暑期在线学术讲座一周回顾(8.9-8.15)
8月9日至8月15日,我院邀请国际知名学者开展6场线上讲座,内容主要涵盖运筹优化与运营管理研究前沿、信息管理与电子商务研究前沿、人工智能领域研究前沿系列领域。

信息管理与电子商务研究前沿系列
TITLE:
More Than Double Your Impact: An Empirical Study of Match Offers on Charitable Crowdfunding Platforms
8月9日上午,来自印第安纳大学凯利商学院的助理教授谭雪为大家带来了题为“More Than Double Your Impact: An Empirical Study of Match Offers on Charitable Crowdfunding Platforms”的讲座。谭老师的研究兴趣主要包括社交网络分析、在线众筹和电子商务等。
讲座伊始,谭老师针对于研究背景给大家做了详细的介绍。在众筹平台上,如何能吸引更多的筹款者以及捐赠者是一个至关重要的问题。“Match Funding”的机制是解决该问题的可行途径之一。具体定义为:在被matcher(通常是第三方的公司或机构)选中的项目中,普通捐赠者捐多少matcher就会以一定的的比例跟捐多少。谭老师及其合作者基于Donorschoose 平台2005年到2009年的公开项目数据分析探究了“Match Offers”带来的影响。

在文献回顾部分,谭老师将关于现有“Match Offers”效果的研究总结为了positive和negative两个大类,谭老师指出在不同的研究背景下,“Match Offers”带来的影响是不同的。在此基础上,谭老师及其合作者对研究内容进行了深入分析和探索,提出了三个研究问题:(1)捐赠者对有无“Match Offers”的慈善项目是否存在不同程度的偏好;(2)捐赠者对“Match Offers”的偏好如何随着他们的捐赠经验而变化;(3)筹款者如何对“Match Offers”的引入做出反应。
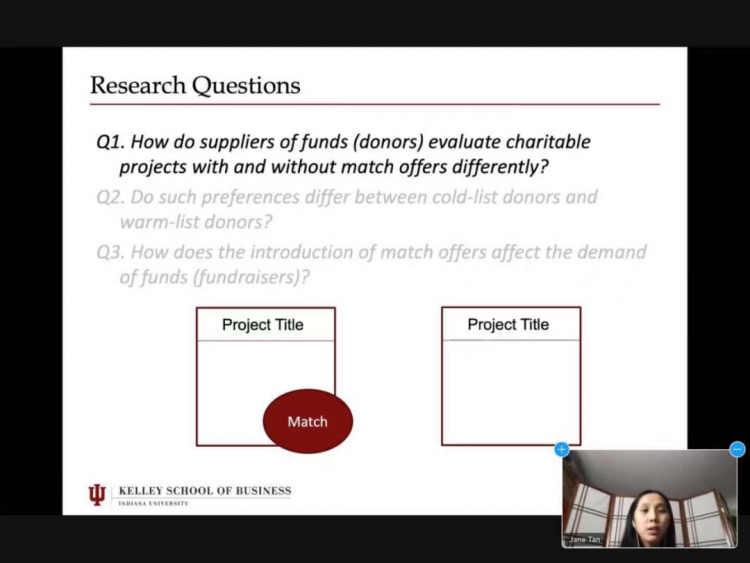
此项研究的框架主要分为三个层面的分析:Individual-level,Zipcode-level以及Transaction-level。在Individual层面,通过对科布-道格拉斯效用等理论模型的变形和推导以及实证分析,谭老师及其合作者成功回答了第一、二个研究问题:(1)平均而言,捐赠者在有“Match Offers”的慈善项目中获得的效用高于没有“Match Offers”的(2)warm-list donors(最近活跃的捐助者)向“Match Offers”项目捐款的可能性是非“Match Offers”项目的三倍,而cold-list donors(较早之前有过捐赠行为而最近没有捐赠行为的捐赠者)这样做的可能性要高两倍;然而,在平台上没有历史捐赠记录的新捐赠者对非“Match Offers”的项目更感兴趣。在Zipcode层面,谭老师及其合作者关注了“Match Offers”项目在所有项目中的比例,回答了第三个研究问题:“Match Offers”项目比例增加 1% 导致需求方(筹资者)要求的资金增加 1.34%,供应方(捐赠者)提供的资金增加 0.854%。关于Transaction层面的研究也得出了和上述相符的结论,作为Robust check,这一层面的结果使研究结论更加地充实可信。

在理论层面,该项研究分析了“Match Offers”对捐赠者影响的异质性并提出了“Match Offers”在market层面的影响,是对现有文献的补充和丰富。此外,根据以上结果,老师也提出了对不同类型捐赠者进行针对性分析、利用matching来提高筹资者参与度等应用建议,具有较高的实践价值。在讲座的最后,谭老师耐心解答了同学们的疑问,讲座在热烈地讨论和交流中画上了圆满的句号。

人工智能领域研究前沿系列
TITLE:
Getting stuff into and out of knowledge graphs: towards bridging the knowledge-language gap
8月9日,学院邀请了澳大利亚莫纳什大学(Monash University)的李元放(Yuanfang Li)教授为大家介绍自然语言处理中的知识图谱的前沿研究。





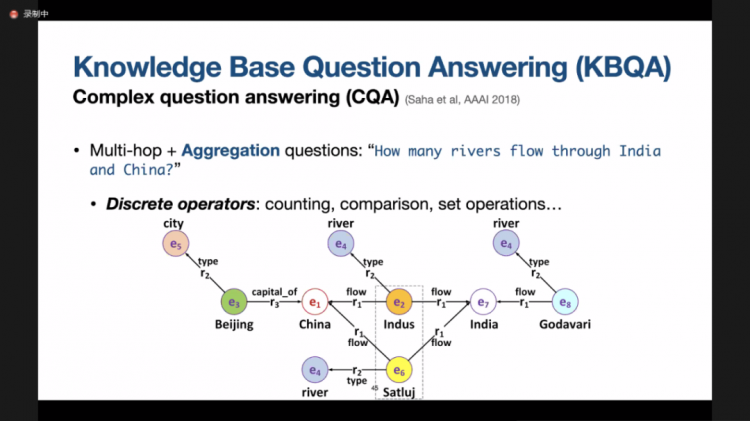


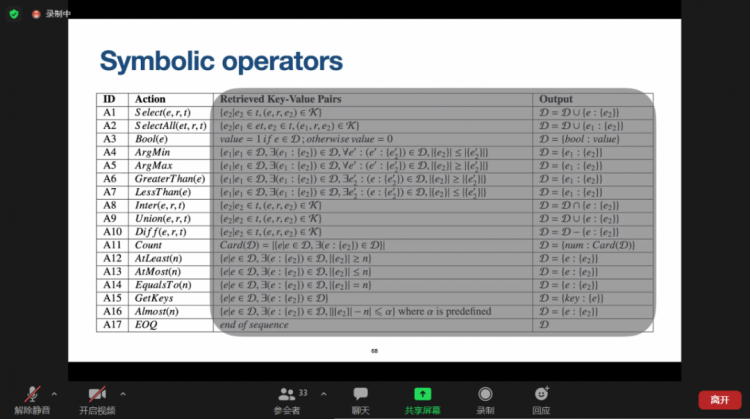

信息管理与电子商务研究前沿系列
TITLE:
Optimal Freemium Pricing and Ephemeral State-dependent Recommendations of Digital Content8月10日,来自弗吉尼亚大学的Natasha Zhang Foutz教授为学院师生带来主题为“Optimal Freemium Pricing and Ephemeral State-dependent Recommendations of Digital Content”的在线学术讲座。张老师带领其团队基于国内一家年收入超2.7亿美元的电子书平台展开了研究,研究内容涉及电子书平台的两个基本策略——免费增值定价策略与电子书推荐策略,该报告对这两个研究项目进行了详细介绍。
第一个研究项目是电子书最优免费增值定价策略研究(Optimal Freemium Pricing)。免费增值定价策略是数字内容平台常用的一个基本策略,它指的是平台免费提供一部分的初始内容(例如,电子书的前若干章)以吸引消费者,并通过向消费者出售后续内容的手段来获取利润的盈利模式。电子书平台在制定免费增值定价策略时面临的一个重要问题是:如何确定电子书的最佳收费点(即从哪个章节开始收费),能够为平台吸引更多消费者,进而创造更大的利润?
现有的电子书收费点确定方法要么是固定不变的(即从固定的章节开始收费),要么就是通过人工的方法来进行评估。采用从固定章节开始收费的方法难以达到经济效益最大化的目标,以人工评估的方法来制定收费点则需要消耗大量的人力物力以及时间成本,当电子书数量巨大时是难以实现的。该研究项目首先依托电子书平台设计了超130万客户的大规模田野实验,确定了电子书样本的最佳收费点;然后,本项目通过文本分析的方法揭示了电子书样本的最佳收费点与书本内容动态(例如,情绪高潮)之间的关系,从而为电子书平台提供了一种自动化、个性化的免费增值定价策略,该策略从期望上能够使平台的年收入提升约50%。

该研究项目的框架图与主要发现如上图所示。
在第一部分,该研究进行了大规模的田野实验来确定电子书样本的最佳收费点,该实验涉及了约130万个客户,及50本随机挑选的电子书。在实验中,客户被划分为一个控制组(依照平台原本设置的收费点进行收费)与五个实验组,接着该研究跟踪了客户在一个月时间内的付费表现,将付费最高的实验组对应的收费点作为了最优收费点。田野实验的结果表明,在50本随机挑选的电子书中,约86%的书籍的最优收费点与平台设置的初始收费点是不同的;另外,若平台按照发现的最优收费点策略进行收费,期望上能够为平台带来50%的利润增长。
第二部分采用了文本分析与统计分析的方法对电子书的动态内容与最优收费点之间的关系进行了分析。具体地,该研究首先使用SnowNLP工具(基于朴素贝叶斯的情感分类器)计算了电子书每一章内容情感得分的均值与方差,用于指示电子书内容的情感高潮点。然后,该研究以消费者的付费值为因变量,付费点相对于情感高潮点的位置作为自变量,以书的特征、消费者特征、作者特征等作为控制变量建立了Tobit Model。经统计分析发现,若将付费点设置在第二个情感高潮点之后,通常能够吸引消费者产生更高的消费。
第三部分则对产生以上结论的消费者行为机制进行了探索。具体方案是,该研究对消费者评论情感与电子书内容情感进行了回归分析,并以回归结果的R2值作为二者契合度的衡量。结果表明,在电子书内容的第二个高潮点后,消费者情感与电子书内容情感的契合度是最高的,若将收费点设置在此时,高度的情感契合度会给平台带来更高的收入。
最后,该研究以收费点为因变量进行了回归分析,并基于回归分析的结果为电子书平台的免费增值定价策略提供了一些建议:对于一些流行的书籍、作者,或高消费的消费者,在电子书内容的第二个高潮点后进行收费是最优的;而对于一些可读性高,价格高,发行时间早的读物,可以将收费点设置得更早一点(例如,第一个高潮点后进行收费)等等。以上结论也表明,收费点的设置不应是一成不变的,受电子书特征、读者特征、作者特征等多方面因素的影响,平台应该设置个性化的收费点。
第二个研究项目是依赖短期状态的数字内容推荐(Ephemeral State-dependent Recommendations of Digital Content)。电商平台使用推荐系统为用户提供商品推荐服务已成为常态。现有的文献通常依据消费者长期的偏好为其进行商品推荐(enduring preference),或是倾向于为消费者推荐同质的、类似的商品(assimilation),或是为消费者推荐不一样的、多元化的商品(diversification)。然而这些推荐策略缺乏变通,忽略了消费者的短期状态影响,容易导致消费疲劳与利润侵蚀,不利于平台的长远发展。
该研究项目立足于国内某电子书平台,首先将消费者的短期状态分为固定状态(fixation)与觅食状态(forage),并对以下研究问题进行了探索与分析:短期状态对电子书消费者的下载与阅读行为有什么影响?短期状态对不同特征的消费者是否具有不同影响?分析消费者短期状态能够为平台的推荐策略提供什么建议?
通过设计实验的方法,我们得以对以上问题进行了探索,在实验开始之前,我们先按照消费者前七天时间内阅读电子书品类的数量对其短期状态进行划分:若其前七天内阅读的电子书品类只有一种,则其短期状态为固定状态;若其前七天内阅读的电子书品类为两种或以上,则其短期状态被标记为觅食状态。实验共设置了一个控制组与三个实验组:对于控制组的消费者,我们总是向其推荐它消费过的类似的商品(always assimilation);对于第一个实验组,我们为其中的消费者推荐多元化的商品(always diversification);在第二个实验组中,我们使用一种与消费者“拧着干”的推荐策略,即消费者短期状态为固定状态时采用多元化推荐,而消费者处于觅食状态时采用相似商品推荐;在第三个实验组中采用的推荐策略与第二个实验组正好相反,是一种与消费者“顺着来”的推荐方法,即消费者短期状态为觅食状态时采用多元化推荐,消费者为固定状态时采用相似商品推荐。接下来,该研究项目采用了回归分析的方法,在该回归模型中,因变量为消费者的下载量与阅读量,自变量为消费者组别的哑变量,控制变量包括书的特征以及消费者个人的一些特征。通过回归分析得出的主要发现为:采用与消费者短期状态“拧着干”的策略(实验组二),能够吸引消费者产生更多的下载量,但阅读量不会增加;采用与消费者短期状态“顺着来”的策略(实验组三),能够吸引消费者产生更多的阅读量并增加阅读时长。
进一步的,我们对不同特征的消费者进行了分析。按照消费者前三个月的行为特征将其从三个方面进行了类别划分:消费者的长期偏好是广泛型的还是集中型的,消费者倾向于白天看电子书还是晚上看电子书,消费者阅读行为一次持续较长时间还是利用碎片化时间进行阅读。该部分实验结果发现:当消费者特征体现为长期偏好较为集中,倾向于晚上读书和利用碎片化时间读书时,采用与其短期状态不一致的推荐策略会使增加消费者的阅读量。


运筹优化与运营管理研究前沿系列
TITLE:
A Riemannian Block Coordinate Descent Method for Computing the Projection Robust Wasserstein Distance
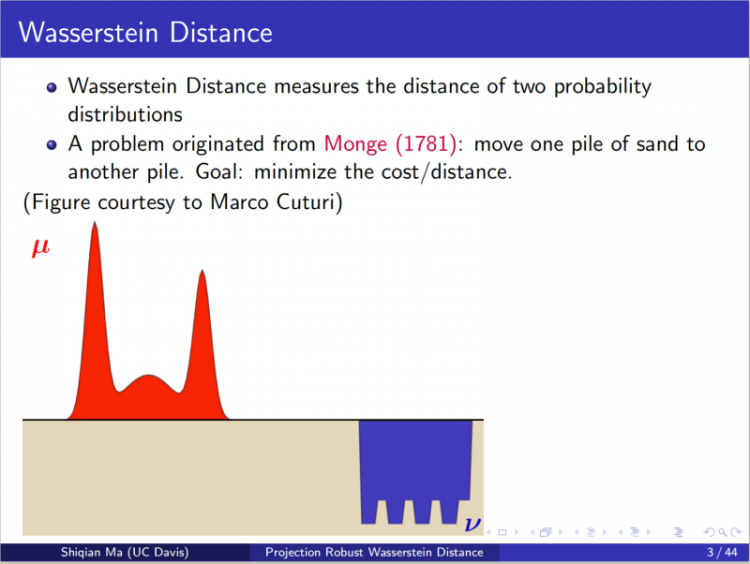
8月11日下午,来自加州大学戴维斯分校的马士谦教授带来了主题为“Riemannian Optimization for Projection Robust Wasserstein Distance and Wasserstein Barycenter”的线上学术讲座。讲座伊始,江波老师对马老师表示了欢迎并向大家介绍了马老师的学术背景。马老师博士毕业于哥伦比亚大学,目前在加州大学戴维斯分校任教,主要研究兴趣为优化理论、运筹学以及其在数据科学、机器学习、统计等中的应用。





人工智能领域研究前沿系列
TITLE:
Ultra-wide Neural Networks and Neural Tangent Kernel
8月12日,学院邀请了华盛顿大学计算机科学与工程学院助理教授杜少雷(Simon S. Du)博士做了题为“Ultra-wide Neural Networks and Neural Tangent Kernel”的讲座。杜博士首先介绍了有监督学习的概念、模型背后应考虑的因素,以及对机器学习进行理论分析的价值。通过杜博士的报告,我们了解到,通过有关Neural Tangent Kernel的理论分析,可以解释两个关于神经网络的神奇现象:第一,即使神经网络的优化目标函数是高度非凸的,简单的梯度下降算法可以找到全局最优解。第二,即使神经网络的参数比数据量还要大,神经网络依然享有极优的泛化性能。






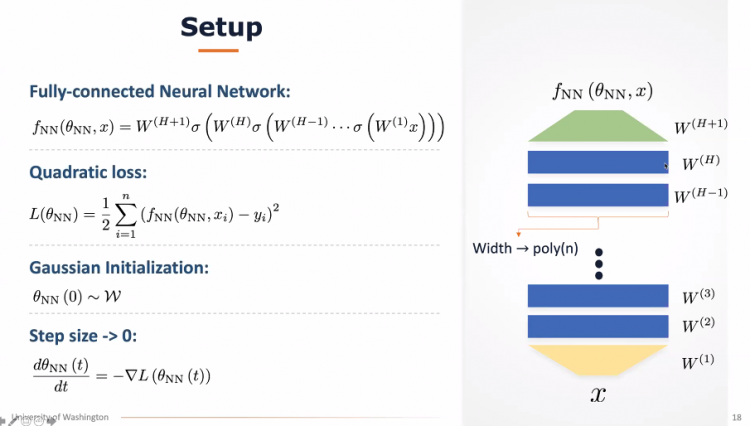
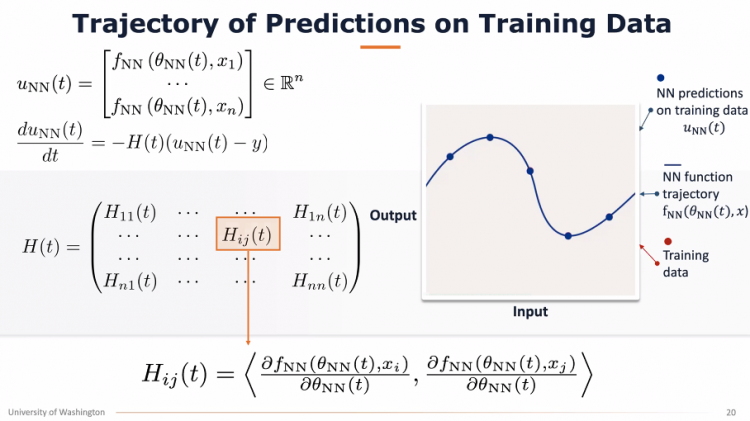




运筹优化与运营管理研究前沿系列
TITLE:
Machine Learning in Strategic Environments
8月13日上午,来自弗吉尼亚大学的徐海峰教授带来了“Manipulating Learning Algorithms in Strategic Environments”的讲座,徐教授的研究兴趣主要是算法博弈和机器学习、数据科学的交叉,在理论计算机和机器学习领域STOC,SODA,EC,NeurIPS,ICML等顶级会议上发表论文近40篇。




文/图:喻洁 曹阳 杨云骢
陈仁杰 肖雯艺琳 李志梅

上财信息

(本文转载自 ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。


备考交流
最新动态
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 06/01 6月活动报名|长江MBA人工智能主题公开课
- 06/01 活动预约 | 与香港大学在职MBA大湾区(香港-深圳)模式校友一起追梦
- 06/02 活动报名|科技前沿X管理创新——华南理工大学前沿论坛暨高级管理人员工商管理全课程项目招生宣讲会
- 06/02 6月2日,MBA公开课暨2025招生宣讲会城市巡展第一站,等你来!
- 06/02 【重磅发布】复旦大学金融新篇章:高阶金融硕士项目发布会邀您共鉴丨AMF
- 06/02 西浦国际商学院国际工商管理硕士IMBA校园开放日
- 06/02 报名 | 创新创业与韧性,教授对话学生暨复旦-BI(挪威)国际合作MBA项目招生说明会
- 06/02 报名中 | 复旦MBA招生交流会@南京站
- 06/04 复旦MBA预审怎样申请?填表指南来了
- 06/05 交大安泰6月5日招生开放日 | 市优毕+在校生一等奖学金+优秀论文得主,商汤HR总监任桐学姐分享宝贵经验,优秀重在一以贯之!










