

上海财经大学信管学院暑期在线学术讲座一周回顾(6.28~7.4)
一周回顾
6月28日至7月4日,上海财经大学邀请国际知名学者开展三场线上讲座,内容主要涵盖大数据应用领域。
危机中的个人主义:
新冠疫情中基于大数据的群体行为分析
7月1日上午,来自弗吉尼亚大学的Natasha Zhang Foutz教授与Jingjing Li教授作了题为“Individualism during crisis: Big data analytics of collective actions amid Covid-19”的线上报告,由此拉开了我院暑期讲座的帷幕。本次报告吸引了上海此案件大学一百多讲师生前来参与,报告过程中大家有问有答,气氛活跃。
在这项工作中,Zhang教授等人首次提出个人主义在危机中具有负面作用。他们利用大数据分析、统计、文本挖掘等多个方法进行研究,对新冠疫情下美国民众的个人主义程度与群体行为进行了分析。本次讲座主要分为5个部分:简介、研究问题提出、数据与度量、实证分析与总结。
Zhang教授首先为大家介绍了疫情期间美国民众的个人主义导致的种种行为,这些行为对疫情控制带来了困难。而与之相反,疫情下群体性行为如戴口罩,居家隔离等行为则有积极作用,由此引出研究动机。本文的主要研究问题是以下三个:
1、个人主义是如何影响疫情中民众的群体行为的?
2、影响的渠道有哪些?
3、结果对政策制定有何启发?两位教授在随后的工作中分别对三个问题进行了解释。

大数据分析与巧妙运用数据信息衡量个人主义倾向与群体行为是本文的亮点之一。Li教授首先介绍了工作中个人主义的衡量标准:Total Frontier Experience。该项指标衡量各个地区在美国西进运动中在边境线上的时间,同时,他们采用了1930年各地区新生儿姓名作为辅助参考衡量个人主义程度。Li教授细致介绍了这些指标的有效性与文献依据,并就此问题与大家进行了深入讨论。疫情中群体行为的衡量借助了大数据的力量,Zhang教授介绍了他们如何利用网站众筹的捐款记录与居民行动坐标数据衡量每个人的群体行为,同时采取文本挖掘,地理匹配等多个方法。另外,Zhang教授也介绍了这些指标在robust test中的表现。
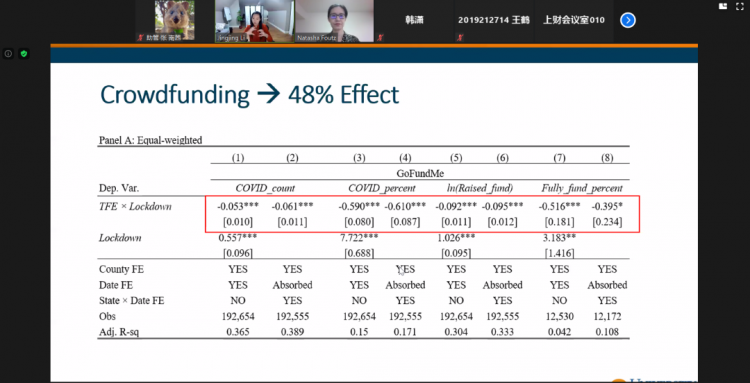
实证分析部分分为county 级别与个人级别,Li教授介绍了DDD模型各个参数的含义,并对回归结果进行了解释,在个人级别上,他们创新性地采用个体原籍所在地来刻画每个人的个人主义程度,对比他们的出行数据作为群体行为。

这份工作回归结果显示个人主义对筹款可以产生的负面影响高达48%,对居家令产生负面影响达到41%。同时后续政府的一些措施对民众群体行为的影响也印证了政府干预对群体行为确实可以产生显著影响。
讲座最后两位教授也给了同学们一些关于如何做科研,如何发现问题的建议,同时也鼓励大家珍惜时间,“How you live through Covid-19 is how you live your life”。
个性化可诠释的消费者移动轨迹隐私保护
7月2日上午,来自弗吉尼亚大学的Natasha Zhang Foutz教授带来了主题为“个性化可诠释的消费者移动轨迹隐私保护”的线上讲座。Zhang教授是弗吉尼亚大学商务副教授,通过大规模数据研究新社会消费者行为和企业数据。
讲座伊始,Zhang教授给大家介绍了当前地理位置大数据的基本情况。地理位置数据在当前的获取有两个特性:准确性、隐私性。地理位置数据有各式各样的来源,其中最主要的来源是手机APP,手机的贴身性决定了数据的准确性。而地理位置数据的信息用途则决定了它的隐私性。目前线下消费者行为研究主要用到的就是地理位置数据。根据单个消费者的轨迹可以预测其购物偏好,根据多个消费者的轨迹可以推断消费者偏爱的购物广场等,有助于精准营销。此外,地理位置数据还能帮助音乐公司根据情景、移动速度推荐音乐,增加用户黏性。
接着,Zhang教授介绍了搭建模型前的准备工作。
首先是数据收集,从消费者和收集者两个方面介绍了数据追踪的可行性。消费者方面,智能手机和目前位置服务的普及性决定了位置数据的丰富性;收集者方面,只需一个权限允许和数据的丰富度、颗粒度、典型性和精确性决定了数据巨大的研究价值。
其次是位置追踪生态系统构建。消费者地理数据流向手机APP,进而流向数据收集公司,数据收集公司进行双边交易,从消费者获取数据,把数据分享给广告商,广告商通过精准投放广告从消费者处获益。
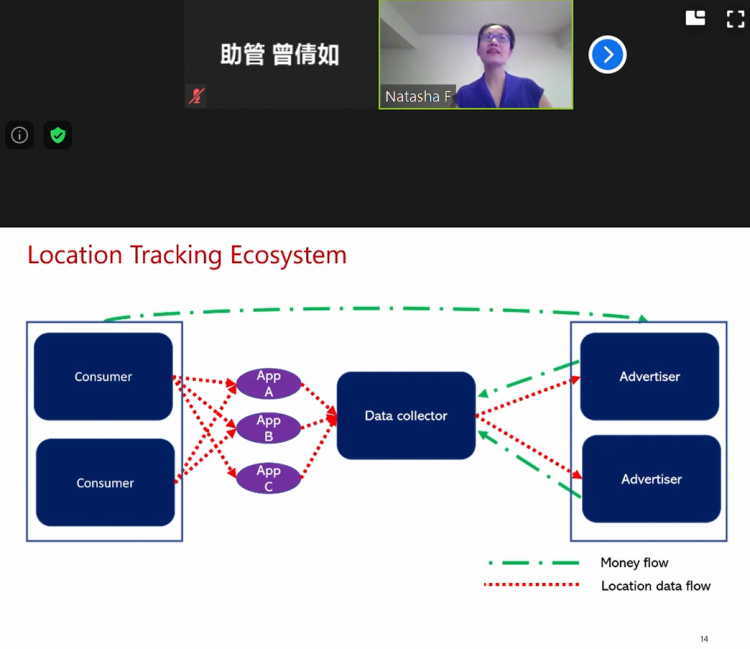
其后,Zhang教授描述了模型需要解决的问题,从消费者、数据收集公司和广告商三方面入手。消费者存在哪些主要的隐私风险?如何量化这些风险?广告商如何让利用模糊数据实现高效用?数据收集公司如何达成合理的隐私-效用权衡?为了解决这些问题,构建了如下框架:
隐私风险方面:进行敏感属性如操作系统、家庭住址等信息推断;处理可能出现的身份重识别问题。数据效用方面:利用POI(Point Of Interest兴趣点)推荐提高数据效用。数据收集公司应该计算用户被身份重识别的概率,并依此决定剔除用户数据点的数量;根据各个数据点出现的频率决定是否剔除该点,频率越高信息量越大,归属用户被重识别风险越高。
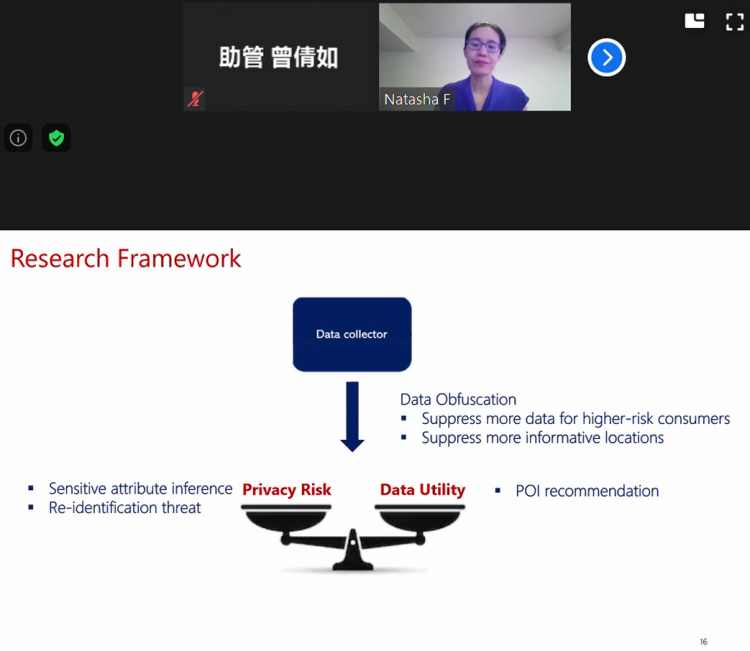
接下来,Zhang教授为大家展示了模型的基本思想:模型目标是在维持广告商效用(u)高的情况下寻找能使消费者风险(r)最小的数据集。首先根据原始数据集T定量计算消费者风险和广告商效用,然后对数据进行剔除等处理,在当前的数据集下重新计算,不断改变p(T)值,迭代这一过程,p越大,r越小,u越小。
最后得到了一条效用减少值-风险减少值曲线,消费者风险减少越多,广告商效用减少越多。数据收集公司可以在两条蓝线之间选择方案。
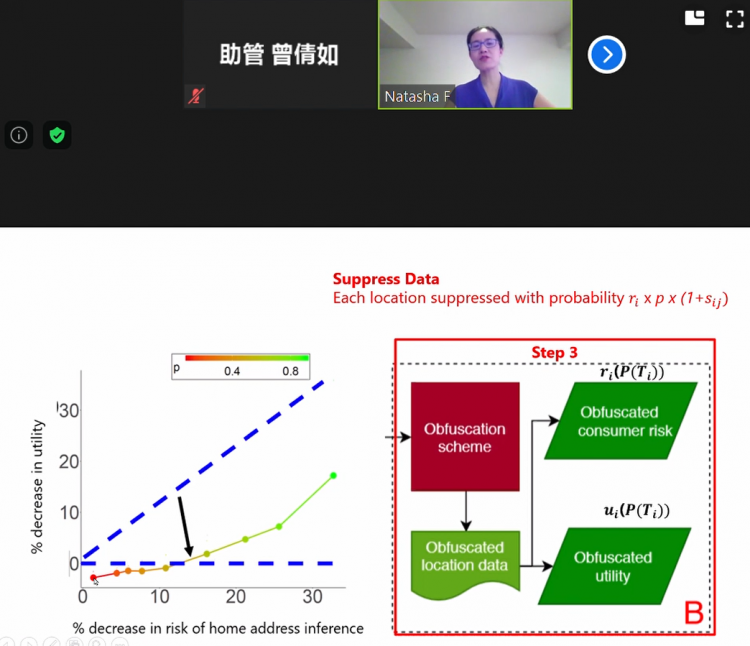
这一模型对家庭住址、操作系统、身份重识别的推断准确率也是较高的。只要知道轨迹中的两个位置就能推算出整个轨迹。这对于广告商的价值是非常高的,利用这些数据有四分之一的几率确定消费者的下一个兴趣点。
灾难如何改变家庭凝聚力
7月3日上午,来自弗吉尼亚大学商学院的Natasha Zhang Foutz教授和她的partner王伟光博士带来了一场高互动性的线上讲座,讲座的主题为“灾难如何改变家庭凝聚力”。
讲座伊始,Zhang教授与同学们一起探讨切身经历的灾难过后的行为变化,引出了本次讲座的主题,即灾难如何改变家庭凝聚力。对于灾难后的行为变化,Zhang教授着重讲述了为什么要研究家庭凝聚力这一种方向。过去人们的生产生活都是以家庭为单位;而当今社会人们的物质上的生产则是以企业为单位,而精神上的生活则仍然保持以家庭为单位。但是值得注意的是,灾难过后的复产复工大部分都是计划好的有条理的,所以不具备有很好的研究价值。另外,精神层面的稳定对于企业营销和政府政策制定也同样具备深刻的意义,所以家庭凝聚力是研究灾后人们行为变化的重中之重。
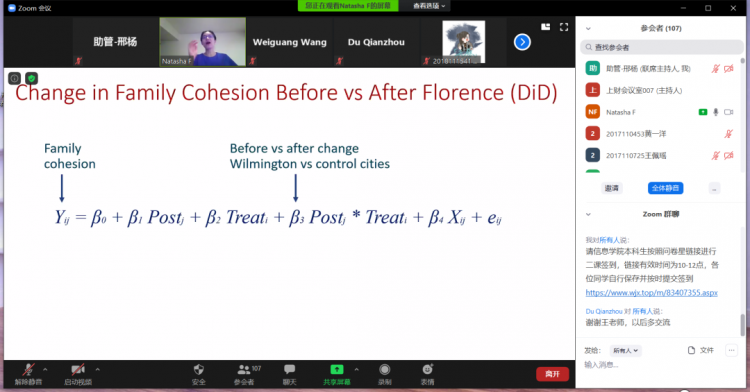
接着,Zhang教授详细地解释了整个项目的研究过程。首先,Zhang教授讲解了如何定义和测量家庭凝聚力。作为一种精神层面的概念,家庭凝聚力难以测量,而问卷调查又具有很强的主观性,因此,Zhang教授团队创造性地采用了地理大数据对用户行为进行研究。地理大数据作为一个数据集,一般有一下几种特征:时间戳、经纬度、用户id。通过对凌晨到黎明这一段正常作息时间的位置截取可以获得每个用户id的家庭住址;而对处于同一个家庭住址的用户视作处于一个家庭。当然,对于邻居和社区这一种可能,Zhang教授团队对其做了鲁棒性的处理。已经获得了家庭和家庭住址,只需要分析用户的地理位置离开了家庭住址或者离开了家庭成员的频繁程度就可以变相的测量其家庭凝聚力。实验部分,采用了DID方法即二重差分分析进行检验,选取了三种城市包括登录城市作为受灾城市、台风路径上的城市作为部分受灾城市、非路径上的城市作为对照城市。城市的选取的标准主要是与受灾城市的人口规模和经济水平相一致。
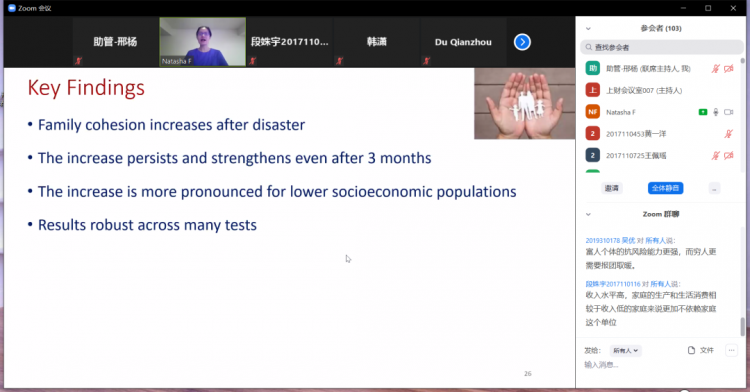
其后,Zhang教授介绍了主要的实验结果,结果表明在城市层面,受灾城市的家庭凝聚力在灾难后悔显著提升并将在未来3个月内保持高水平。在社区方面,对于高学历高收入的人群,这种受灾增强家庭凝聚力效应不是很明显。最后,Zhang教授介绍了验证该结果的鲁棒性所采用的一系列实验,并为参加线上讲座的师生们进行答疑。在直播间激烈的讨论和大家的掌声中,讲座圆满结束。
(本文转载自上海财经大学信管学院 ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。


备考交流
最新动态
- 信息管理与工程学院 | 上海财经大学2024年MEM项目(非全日制)调剂通知 2024-03-30
- 24招生 | 上海财经大学2024年工程管理硕士(MEM)(非全日制)招生简章 2023-10-23
- 上海财经大学讲座回顾|人工智能技术在经管领域的应用 2023-04-17
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 04/02 暨南大学MBA名师公开课丨解析AI数字人跳舞视频——制作实操及变现路径
- 04/06 活动报名|投资风险与回报的掌控,港科大MBA大师课助你了解交易的智慧
- 04/06 这所双一流有调剂!云南大学EMBA/MTA调剂政策官方解读来了!
- 04/06 报名 | How your Firm will Shape the Future?“小火车”教授公开课暨复旦大学-BI(挪威)国际合作MBA项目说明会
- 04/08 今晚7点!哈尔滨工业大学商学院调剂说明会直播预约开启
- 04/10 4月10日招生开放日 | 第一批面试前最后一场,交大建筑本科学姐与你分享职业转型经历
- 04/11 【活动报名】4月11日@清华大学|2024科创产业投资峰会:硬科技、智能造、创未来
- 04/11 活动报名 | 中欧思创会洛阳站,聚焦智能制造
- 04/12 活动报名 | 香港中文大学(深圳)金融EMBA校园开放日暨24级课程说明会
- 04/12 长江MBA公开课:AI驱动下的企业变革|活动报名










