

观点 | 陈玲:可接受公平——全球算法治理的共识起点
CIDEG
由清华大学主办,联合国开发计划署(UNDP)作为国际支持机构的2021人工智能合作与治理国际论坛12月4-5日在清华大学举行。此次论坛吸引了来自全球相关学术机构、高校、国际组织、企业等几十家单位共同参与,为如何构建一个平衡包容的人工智能治理体系建言献策。
本次论坛下设三大主论坛,围绕“如何构建一个平衡包容的人工智能治理体系”“人工智能技术前沿与治理”“元宇宙未来治理前瞻”展开讨论。同时还设七大专题论坛,探讨人工智能伦理与治理中的跨文化信任、在相互依存的全球数字时代弥合数字鸿沟、人工智能与国际安全、人工智能与气候行动、人工智能与算法公平、国际数字治理与企业可持续发展、人工智能与社会发展等热点话题。
“建立一个全球算法治理的共识起点,寻求最低限度的可接受公平。”
12月4日,清华大学公共管理学院副教授、清华大学产业发展与环境治理研究中心主任陈玲出席2021人工智能合作与治理国际论坛,并在“人工智能与算法公平”专题论坛上作主旨演讲。
我们特将发言内容整理如下,经其本人授权,全文分享给读者。

陈玲
清华大学公共管理学院长聘副教授,清华大学产业发展与环境治理研究中心主任
“
发言实录

陈玲主任做主旨演讲
感谢主持人于洋教授,感谢各位嘉宾参与”人工智能与算法公平”专题论坛。我今天演讲的题目是“可接受公平:全球算法治理的共识起点”。人工智能的合作与治理是一个全球性的问题,这两天的论坛集中讨论了AI治理的方方面面,很重要的一个目标就是建立人工智能治理的全球合作框架。我今天的发言希望是抛砖引玉:建立一个全球算法治理的共识起点,建立最低限度的可接受的公平。
今天早上,我问我14岁的儿子——一个AI编程的狂热爱好者,你怎么看待算法公平问题?他塞着耳机、从电脑前抬头反问我:“算法公平?算法没有歧视或者公平的问题。那是人的问题,不是算法的问题。”在孩子看来,算法是非常诚实的,你让它做什么、它就给你做什么。我想这是非常典型的技术中立的观点,认为算法只是技术和工具,而如何使用这个技术和工具,人类需要达成共同的规则和共识。
的确,正如我儿子所言,算法借助大数据和算力大大提高了信息处理效率,也提高了准确度和客观性,某种意义上讲,算法模型呈现出来的就是客观事实,和客观事实具有高度一致性。但不可否认的是,AI算法在现实中,特别是在汽车和医疗保险、犯罪风险审查、就业招聘等广泛的领域里都引起了公平性争议。
一方面算法应用带来很多社会不公正,另一方面算法作为一个技术,只是客观的呈现了现实世界中的不公平。提高算法公平必然就会损失一部分效率,比如说我们在进行犯罪风险审查的时候,不再用那些敏感信息进行审查,包括像个人性别,居住地,种族,犯罪历史等,势必会降低算法准确度,这样会带来社会风险,包括公共安全风险的提高,从而带来更高的社会成本。因此,算法公平和效率其实是一个权衡问题。
算法歧视
算法歧视从何而来?我们如何仔细分析的话,可以发现算法歧视有三个来源:数据,算法和人类行为。有些源自数据的歧视是历史造成的,比如说企业领导人数据库中女性CEO非常少,那么根据这个数据库训练出来的一些算法模型,一定会带有性别歧视在里面,因为对于女性的数据本身就是少的;同样,其他数据库的采样过程,以及样本库的覆盖面等,都会带来源自数据的算法歧视。还有一种数据造成的算法歧视,实际上是由数据总体和局部特征的差异带来的,我们称之为辛普森悖论。例如城市“剩女”似乎特别多,但实际上总体而言中国人口结构是男性大大多于女性,这是总体和局部数据特征不同。其次,有些算法歧视是计算机程序(即狭义的“算法”)造成的。算法在测量、打标签、分类、排序、评估等环节,可能会带有一些算法设计者所考虑的规则自身偏差。第三种算法歧视的来源,也是最根本的原因,是由人类行为自身造成的。由于人类行为有自我选择偏差、关注度偏差、文化差异、制度差异等因素,体现在AI上,就转化为算法歧视。例如社交媒体中大V,受到的关注度特别高,人就会自然而然的认为大V讨论的议题或观点非常重要;还有不同的文化,不同的制度,人类行为自身带来的歧视是最重要的部分。
我们也可以把算法歧视根据其结果分为不同的类型。第一种分类是分为直接歧视和间接歧视。有的会形成直接歧视,比如像性别、种族等等个人的敏感信息,会带来对个体直接的伤害,这样的算法就会带来直接歧视的影响。而有的是间接性的,带来整个社会成本或者是整个群体的区别对待。第二种分类是有意的歧视和无意的歧视。有意的歧视容易监管和规避,而无意中造成的歧视是通过数据算法和人类行为长期积累的一个发现知识的过程,通过算法揭示出原来不知道存在的歧视。第三种分类是可解释的歧视和不可解释的歧视,前者可以通过算法修正,但对于不可解释的歧视,现有的算法技术和治理机制可能是无能为力的。因此,我们从来源和结果来看,算法歧视有不同的类型,在治理或者应对歧视上,就应该采取不同的措施。
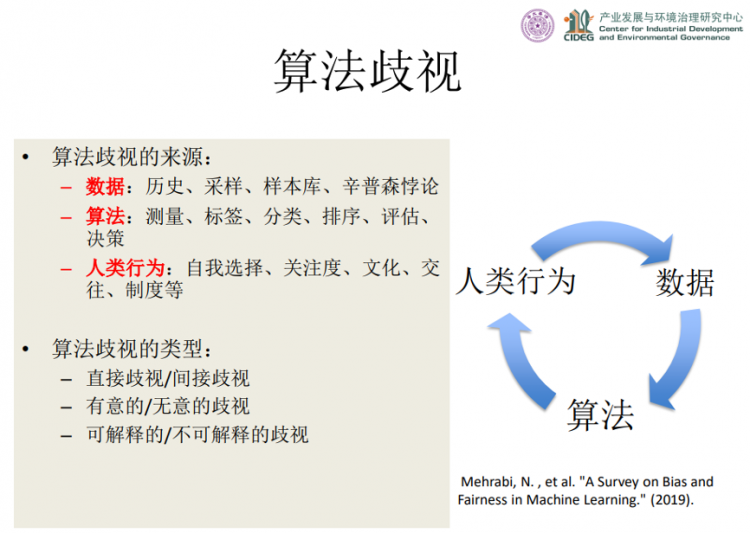
算法歧视的来源与类型(陈玲,2021)
算法公平
在了解了算法歧视后,我们就要思考,应该怎么建立一个算法公平?公平这个词特别难以定义,哲学、心理学、社会学、政治学等学科对公平有着长期研究。唯一可以确定的是,不同的学科和文化对公平的理解非常不一样。
大致而言,我们可以把公平分为起点公平,过程公平,结果公平。有的人认为就是在起点上,如果每个人拥有相同的初始禀赋,针对所有个体都不带预设和偏见,那么决策就是公平的,这就是起点公正。有的认为过程公正才是可取的,只有保证过程是一样的程序、一样的竞争规则,最后结果的个体差距就是正当的。还有的人认为,每个个体拥有相同的发展权利,应当拥有同等的生存和发展的资源,这就是对结果公平的要求。体现在算法上,计算机科学家们用很多方式计算公平,比如说概率相等,结果统计平均值相等,或者未知参数公平,后者就是把那些我们认为带来歧视的敏感信息隐掉,不作为决策参数,这样的决策就是公平的。也有的是用相同的程序保证公平,或数据子集的均值相等。但是要注意到一点,我觉得特别令所有研究者纠结的是不同的公平观是内在冲突的,不可兼得的。既想要起点公平、过程公平,又想要结果公平,这是不可能实现的。
在相互冲突的观念和计算方法里如何进行抉择?答案其实就是找到可接受公平。如果人们希望任何由AI算法带来的歧视都应该被消除掉,我认为这是一种不合理的期待。如DIKW金字塔(参见下图)所示,算法不仅仅是数据收集和信息生成的工具,而且还是一个知识生产和价值分配的机制。知识生产和价值分配的过程实际上是一种经济活动和社会交往的过程。只要是涉及不同主体的经济活动和社会交往过程,人们就不得不寻求相互之间的理解,妥协和共识。因此,在算法公平里寻求一种最低限度的、共识性的可接受公平,就是我们进行全球算法治理的起点。
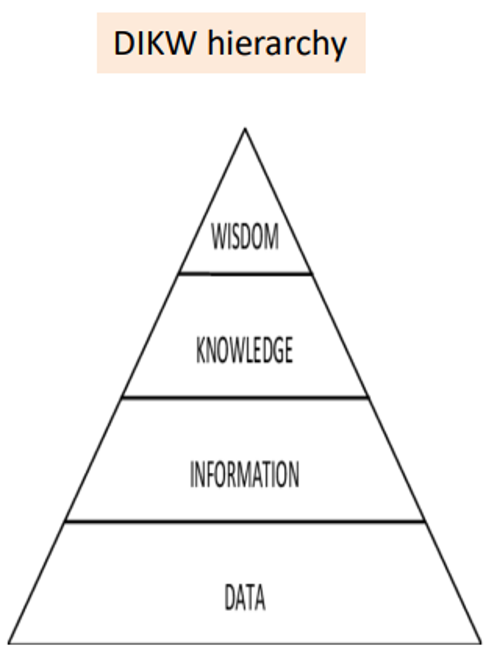
DIKW层次结构图(Ackoff, 1989)
随着技术嵌入到社会生活和经济活动过程不断深化,可接受公平的最低限度也是动态演进的。
可接受公平:基线、调适和救济
首先,让我们来画一个可接受公平的基线(baseline)。
在数据层次上,首先是保证数据集的完整性和准确性,这是一个起点公平的必要要求。其次就是保证数据集在收集过程中开放的、透明的,即允许新的数据能够进入到数据集。上述两点是保证在数据层面上的起点公平。
在算法层面上,我们希望能够达到过程公平的基础,算法的程序应当是透明、可追溯和可问责的。透明就是提供了验证的机会,而可追溯就是要求在算法程序里切入一些检查点,这些检查点能够使得过程可追溯。可问责就是使每个数据产生、计算、以及应用的过程都有特定的责任主体,即可追责的责任主体。上述准则能够保证算法的过程公平。
在人类行为层面上,人们希望算法结果用于智能辅助决策达到一种结果公平,但是真正的结果公平是很难实现的,我们从最低限度的结果公平来看,应该是可计算的,可预期的,可解释的结果。我们在购买汽车保险或者医疗保险的时候,实际上完全可以接受不同年龄、不同性别的人,付不同价格的保险费。这体现了经济效率。但是我们为什么愿意接受歧视性定价的保险费呢?因为我们知道这个保险费的计算是基于大数据人口的预期寿命和事故发生概率等,这个概率的成本是可计算的,而我们的收益也是可预期的。在这个基础上,如果算法结果也是可计算、可预期、可解释的,这就使人们能够在接受结果上感到公平。
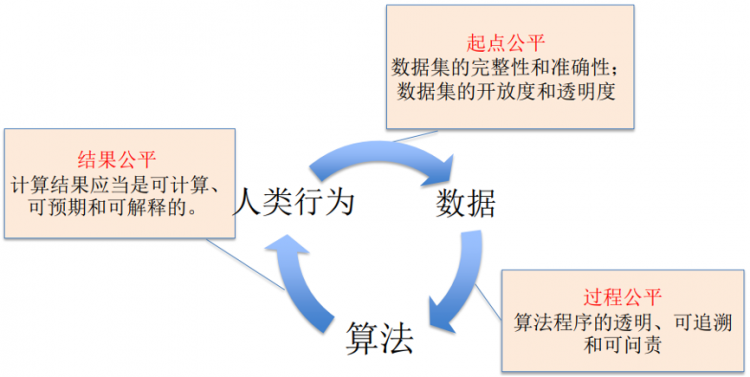
可接受公平的基线(陈玲,2021)
其次,在基线上我们希望对可接受公平进行一定的调适。在起点公平上,我们会碰到敏感信息保护和删除这样的问题。例如,删除大量的敏感信息,包括性别、种族、经历等等,反而会提高监管的难度——监管者无从知道该算法是否对特定性别、种族的人造成歧视性对待。我们希望通过一些技术的手段解决,如区块链、非对称加密、可信计算等。在过程公平中,提高算法透明,追责和可追溯,会带来一些商业秘密和知识产权保护的问题,需要在数据确权以及其他的新信息信任机制上给予突破。在结果公平中,由于解释结果或者理解结果的专业知识是不均等分布的,在这样的专业性知识存在社会分工的基础上,应该寻求多元、不同组织的治理模式。
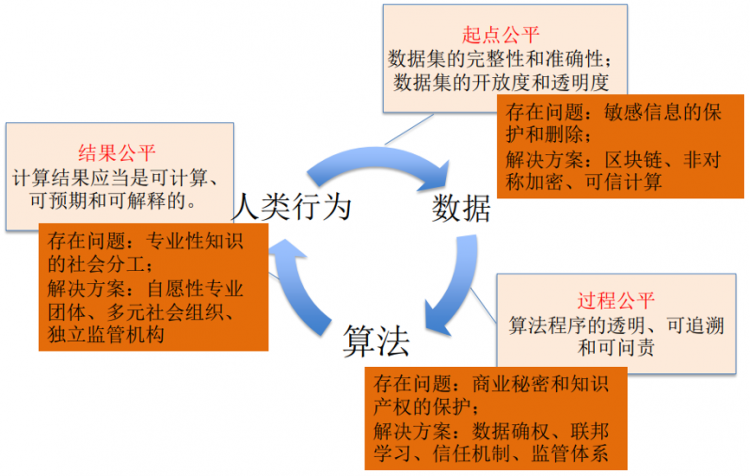
可接受公平的调适(陈玲,2021)
另外我们也希望能够在数据确权基础上,基于不同的产权,像私人物品、集体物品或者公共物品,对数据、算法和人类行为有差别地制定可接受公平的具体准则。
最后,我们即便做到了可接受公平的基线和调适,AI算法仍然会产生不合宜的结果,这是技术秩序与社会秩序的本质差异造成的,是无法避免的。就像市场秩序会带来市场失灵一样,需要用政府干预来纠正市场失灵。算法歧视是技术秩序嵌入市场和社会秩序的结果,完整的可接受公平还应该包括事后救济等干预措施。在数据、算法和人类行为三类来源的算法歧视上,应该有各自的救济准则和措施(如图)。
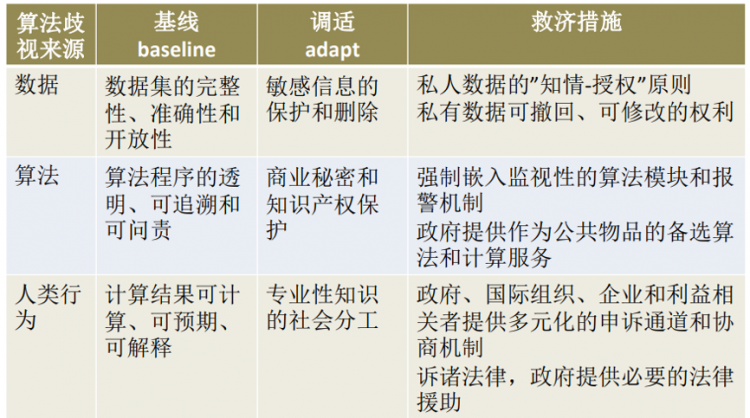
可接受公平的整体框架(陈玲,2021)
结 论
总结一下,我今天的报告有如下几点结论:一、算法歧视来自数据、算法和人类行为,本质上是技术秩序的集中体现,无法根除。二、不存在“算法公平”的一致性观点,消除算法歧视努力将带来社会成本,两者需要进行审慎的取舍(trade-off)。三、我们应倡导“可接受公平”的理念,寻求最低限度的、可接受的公平准则。四、可接受公平准则具有调适性,最低限度的可接受公平准则将随着技术发展和人类社会互动的过程而演进。最后,政府对算法歧视进行干预和救济是必不可少的。
讨 论
陈玲主任主旨演讲后,清华大学交叉信息研究院助理教授于洋主持开展圆桌讨论。圆桌论坛嘉宾包括:亨氏信息系统与公共政策学院机器学习系数据科学与公共政策中心主任伊德·加尼(Rayid Ghani)、科幻作家陈楸帆、麻省理工学院斯隆管理学院运营管理助理教授丹尼尔·弗洛伊德(Daniel Freud)、联合国妇女署项目和伙伴关系专家毕文韬(Birat Lekhak)。专家们就“能否通过纯技术手段实现符合道德的人工智能”、“算法数据收集中的隐私风险”、“算法设计中目标的选择与权衡”、“AI应该如实反映还是矫正现实中的歧视”、“如何平衡各群体承担的消除歧视的新技术开发成本”等问题展开了精彩讨论。
供稿丨清华大学产业发展与环境治理研究中心
(本文转载自 ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。
热门推荐


备考交流
最新动态
- 清华大学-香港城市大学MPA-EMBA项目2023年毕业活动成功举行 2023-07-03
- 清华大学2024年公共管理硕士(MPA双证)研究生招生通知 2023-04-20
- 首届中国数字经济发展和治理学术年会演讲精粹系列二 数字时代的经济发展与学科建设 2023-03-01
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 05/04 报名 | “中国经济变局下的企业风险管理”复旦大学李若山教授公开课暨联合宣讲会
- 05/08 集赞赢取精美礼品 | 面试诀窍、备考经历、海外交换,报名5月8日面试圆桌派,用10个问题揭秘三位高分学长的备考秘籍!
- 05/12 招生工作|浙工大校园开放日暨MBA、MEM项目宣讲会通知
- 05/12 「复旦大学 EMBA 项目」与「复旦-台大 EMBA 项目」介绍会 | 活动预告
- 05/17 限时抢位!长江商学院MBA项目5月北京体验课
- 05/18 5月18日 | 全国首场中国商学院招生巡展暨2025招生政策发布会(北京站)重磅来袭!
- 05/18 5月18日 | 北京体育大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 中国矿业大学(北京)邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 北京师范大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 天津大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)










