

清华师说 | AI引领组织革命:清华李宁教授分享人机互动如何影响知识型员工
清华大学经济管理学院领导力与组织管理系Flextronics讲席教授、系主任李宁教授近日做客由阿里巴巴人工智能治理与可持续发展研究中心(AAIG)联合高校和产业界发起的AI治理交互栏目《追AI的人》系列直播第31期,分享《人机协同、效率与创新:AI时代的组织模式探索》。现转发直播的文字回放,以飨读者。

分享大纲
生成式AI对工作效率和创新的影响
人机互动前沿研究最新进展
人机互动对效率影响的实验证据
人机互动对效率创新影响的内在机制
人机互动的未来展望

过去的一年里,以GPT为代表的生成型AI非常火爆。很多研究都从技术的角度比较了不同的大型语言模型,以了解它们在完成任务方面的能力差异。而今天的分享将主要从人的视角出发,因为我们知道人是使用AI的工具,在技术之外,人在这个过程中扮演着非常重要的角色。
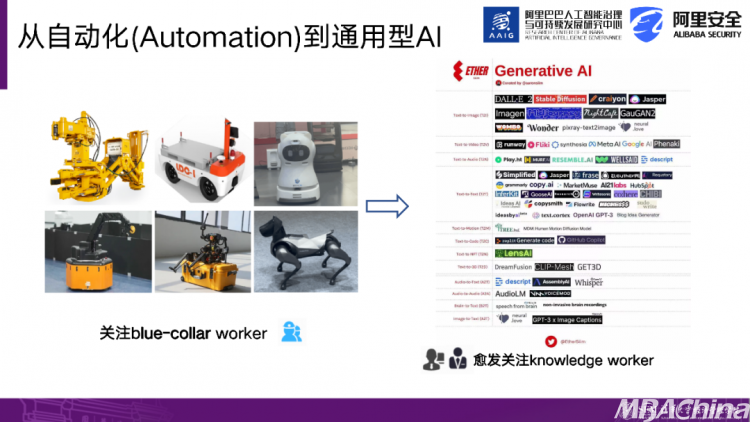
先介绍一下背景,在今年之前,我们对AI的关注度并没有像现在这样高涨。当我们提到AI这个工具时,我们更多地想到的是一些实体机器人,比如酒店或餐馆中端盘子的机器人。在那时,人工智能更多地影响的是蓝领或体力工作者。然而,随着生成型AI的出现,它首次对知识型员工(白领员工)产生了巨大影响。
可以毫不客气地说,对于一些尚未普及自动驾驶技术的外卖骑手或司机等人群来说遥遥无期,但是对知识型员工的替代迫在眉睫。今天我们的重点是人机互动如何影响知识型员工。许多人可能也使用过一些AI智能助手,因此我们先来看一下具体的背景情况。

关于生成型AI,麦肯锡进行了一项研究报告,对比了两类不同类型的工作——一类是偏向白领的工作,另一类是偏向蓝领的工作。
可以观察到,在体力工作者身上,生成型AI的影响几乎微不足道。然而,对于传统意义上需要做决策、进行人机协作等工作的知识型员工来说,生成型AI的出现产生了显著的影响。我们可以看到,在生成型AI的影响下,相对于传统的自动化路径,出现了一种增量的变化。

当然,还有一些其他的新闻报道进一步说明了对知识型员工潜在冲击的情况。例如,加州伯克利大学的一位教授预测,在2030年,GPT可以在一天内学完人类需要几千年才能掌握的知识,甚至可能接管美国30%的工作时间。

看起来,通用型人工智能的时代已经来临了,但实际情况并不如理想中那样。生成型人工智能加速了传统自动化过程的进展。同样是麦肯锡的一份报告中,提出了两种不同的未来情景,并进行了两种预测:在乐观情况下,如果公众对人工智能的接受程度高,法律法规也支持等一系列理想情况下,生成型AI对社会自动化的加速程度将达到15%。
然而,在一个不太乐观的情况下,到2030年可能只有1%的影响。目前市场上有很多关于这方面的热议,声称AI的影响非常大。但实际上,当它真正应用到企业内部的管理过程中时,可能会发现影响并不那么显著。这与我们目前进行的一些实验结果也是相吻合的。
在应用生成型AI或通用型AI时,我们面临许多挑战和障碍,特别是在处理数据方面。例如,路透社报道了Chat GPT的爆炸式增长已经遇到了瓶颈。我们可以看到许多工作并没有完全采用这些大型语言模型,但它们的发展已经达到了瓶颈。那么下一个增长曲线在哪里呢?这是一个严重的问题。

我们面临哪些挑战?从分析来看,有几个方面需要考虑。首先是从个人层面来看,如果大家曾经使用过生成型AI,可能会有以下体验:初次接触AI时,你会发现它非常神奇,可以自由流畅地用人类的语言与你进行对话,甚至可以帮你写诗或撰写简单的工作报告。然而,随着时间的推移,你会发现这个技术很难实际应用于我的工作中。尽管它看起来很强大,但与我的工作实际上存在很大的差距,很难达到预期的效果。
从组织层面来看,这个问题变得更加严重。我们需要思考如何与组织现有的工作流程相融合,同时还要考虑数据隐私和法律合规的问题。
从系统层面来看,我们需要考虑如何将这种技术与已有的数字化系统进行整合。许多企业已经完成了数字化转型,拥有各种数字化系统,如IT系统、人力资源管理系统和财务系统。在这些系统之上,如何叠加生成式AI?我们了解到一些企业的做法是接入生成AI的API,并在前端创建一个聊天机器人供员工提问。然而,员工可能只会使用几次后就再也不使用这个功能了,导致这个功能无法真正发挥作用,出现了一种分割的现象。
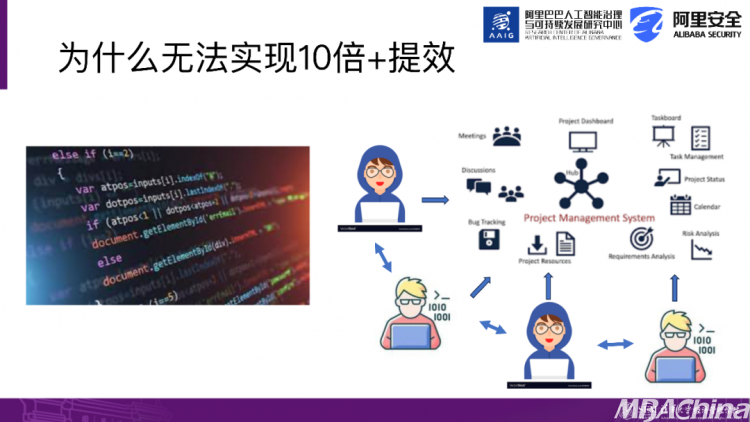
让我们来分析一下这个问题。为什么Chat GPT无法实现所谓的10倍+或者百倍+的提效呢?以前,我们编写一篇文章或者初步代码可能需要几个小时,而如果让Chat GPT来完成这个任务,可能只需要几秒钟甚至不到半分钟。
从理论上讲,它具备这种10倍+提效的潜力。举个例子,假设一个软件开发工程师,现在很多生成AI可以作为代码生成的助手,但实际工作远比这复杂。如果我只负责一个模块的开发,使用Chat GPT或其他生成式AI确实可以迅速完成初稿,实现了10倍+的提效。
然而,如果从整个开发系统来看,它是一个复杂的集成功能,涉及不同程序员之间的协作和不同模块的整合。就单个模块而言,确实可以实现10倍+的提效。但如果考虑到每个人对系统的贡献以及程序员之间的互动情况,综合计算后可能只能得到1%、2%,甚至可能比不使用AI还要低。

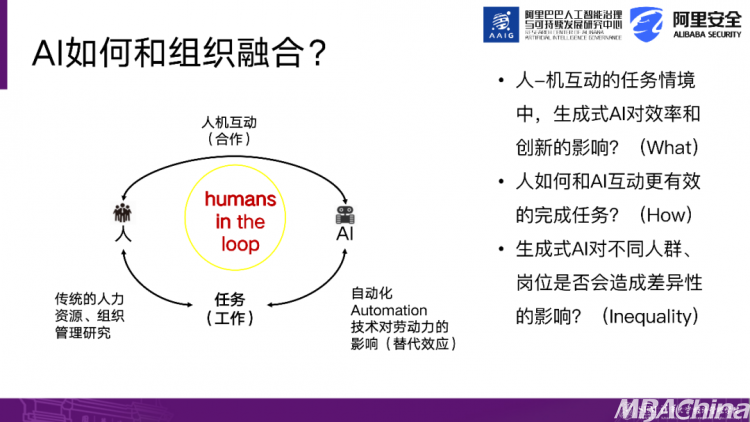
接下来的章节将分享一些最新的国际研究,重点是研究人与AI之间的互动,以及对效率和结果的影响。先看理论框架,过去的组织管理研究关注的是人与事之间的结合。事可以是任务或岗位,在职场中充当载体。这衍生出传统的人力资源管理实践方案、组织行为学研究以及领导力等领域,这些研究都旨在协调人更好地完成工作任务,将人与任务相结合。
随着AI的出现,一些学派或研究开始探讨AI与事的关系。其中,自动化是典型代表,比如在生产线流水线上的AI直接执行任务,如自动驾驶和无人机送快递等,AI与任务的连接。这些研究主要讨论技术对劳动力的影响,即技术是否替代还是增强。由于生成式AI的载体是语言,因此语言决定了人与AI之间有效互动的能力,人与AI形成合作关系,共同完成工作任务。
因此,出现了一个术语"human in the loop"。在讨论生成式AI时,我们不能将人与AI分开,必须考虑到人与AI互动的结果。在我们的研究设计中,有两个因素对技术和人的投入起作用。技术方面包括技术的升级、技术能力和算力等,而人方面包括培训和对人力资本的投资。这两者可能相互促进,相辅相成。因此,我们接下来分享的研究都从人机互动的角度出发,探讨人与AI如何合作,而这种合作将产生怎样的结果。
我们首先关注的问题是在人机互动任务情境中,AI对效率和创新的影响。过去的AI研究更加注重效率,并对其影响进行了研究。然而,生成式AI具有智能涌现的特点,因此在人机互动中,创新不再是人类特有的特质。当人与AI进行互动时,可能会出现创新性的结果。
这引发了一个问题——what即是什么?首先,我们需要了解人与生成式AI之间的互动对结果产生了什么影响。其次,我们需要探讨人与生成式AI之间的互动机制如何能够更有效地产生结果。如果你曾经使用过生成式AI,你可能会有这样的感受:别人使用生成式AI可以高效、高质量地完成许多任务,但是当你与生成式AI交流时,你会发现它表现愚笨,无法满足你的要求,这涉及到互动机制的问题。
第三个问题是生成式AI对不同人群和岗位是否会产生差异性的影响。公平性的讨论涉及到不同的人在AI浪潮中获益不同,即谁会受益,谁会受损。哪些岗位将被取代,哪些岗位将被增强,这是一些基本问题。
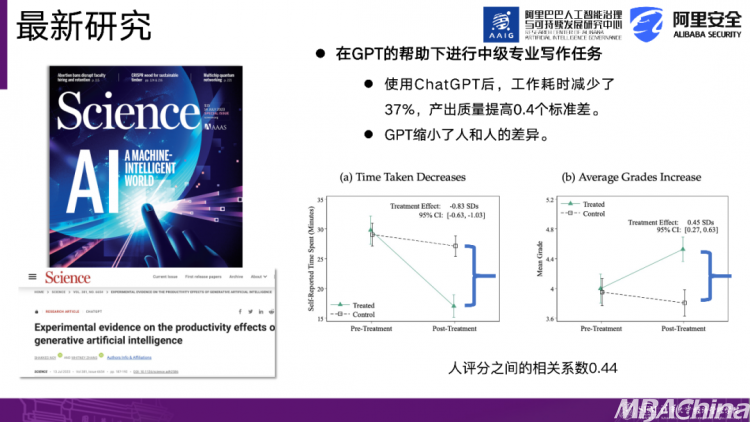
首先,我们来看一篇发表在《Science》杂志上的研究文章。该研究设计了一项实验,将参与者分为两组,一组使用了Chat GPT,另一组没有使用。然后观察使用Chat GPT对任务完成效率和绩效的影响。这些任务是一些职业化的写作任务,比如新闻稿和求职信等,这些任务在工作场景中很常见。
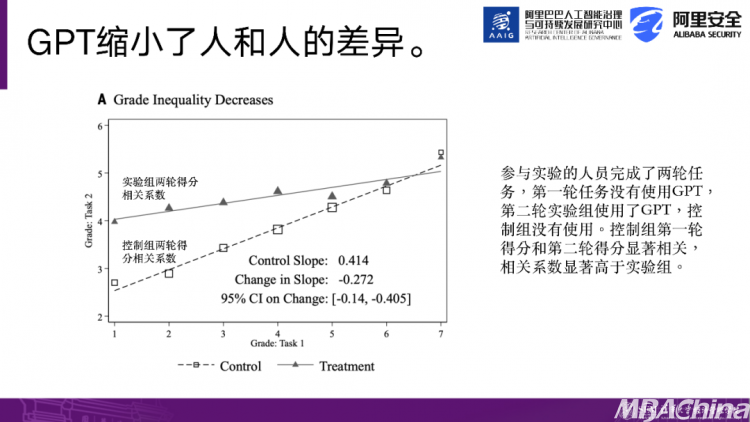
该研究得出了几个结论:第一个结论并不出乎意料,即相较于未使用Chat GPT的组,使用了Chat GPT的组在完成任务时所用时间减少了37%,同时产品质量提高了0.4个标准差。这一结论表明,在写作方面,使用Chat GPT确实能提高人们的效率。
第二个研究结果非常有趣,它指出使用Chat GPT可以减小人与人之间的差异。那么我们如何解读这个结果呢?在参与者的能力上可能存在差异,例如某些人的能力较强,他们在完成各种任务时表现也较好。在引入了Chat GPT之后,出现了两种观点。一种观点认为,Chat GPT会放大人与人之间的差异,即如果我能力较强,在使用了Chat GPT后,我的能力会更加突出,因此与你的差距会更大。第二种观点认为,在使用Chat GPT之前,参与者的能力本来就存在差异,但使用之后,大家的能力反而变得相近。生成AI工具将大家带到了同一起跑线上。
该研究发现了支持第二种观点的情况。例如,在第一次任务中,未使用Chat GPT作为基准进行能力评估,然后在第二次任务中,一部分人不使用AI,另一部分人使用AI。研究发现,在未使用AI时,参与者的前后两次任务得分相关性较高,即能力较强的人在第二次任务中得分更高。然而,在使用了AI之后,参与者的前两次任务得分相关性降低了,相当于优秀的人在使用AI后,与那些不太优秀的人的能力变得差不多,拉平了人与人之间的能力差距。
然而,这篇文章也存在明显的局限性。首先,它仅仅使用了单一的写作任务作为研究对象,而Chat GPT在文本生成方面表现出色,因此该文章对人与AI互动的过程观察较少。在许多情况下,人给出一个提示词,AI生成结果,然后进行轻微的编辑,作为最终报告的成果。实际上,这篇文章没有充分观察到人与AI互动的结果。此外,该研究的任务范围较为狭窄,无法反映出事件的复杂性。

另外还有一项研究探索了生成AI在各种任务中的边界属性。这篇文章的创新之处在于将任务分为两类。一类是在AI能力范围内的任务,另一类是在AI能力范围之外但对于人类可能相对容易完成的任务。这两类任务的难度相近,但基于任务属性的不同,一类在AI能力范围内,另一类对于AI来说较为复杂且具有挑战性。
AI擅长的任务——创造性任务。例如,在某个尚未受到足够关注的特定市场或运动领域提出10个创意点子,此类任务是AI擅长的,因为它涉及到创造力的工作。然而,AI不擅长的任务是基于详实数据和访谈给出一个准确答案,即需要根据这些数据指向一个正确答案的任务。我们经常说AI一本正经地胡说八道,它无法给出正确答案。
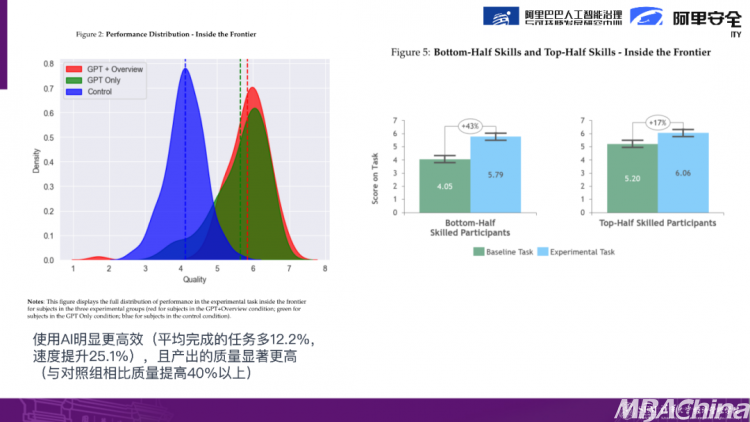
因此,这项研究得出了结论:对于在AI能力边界内的任务,使用AI可以增加平均任务完成数量增加12%,提升25%的速度,并且产出的质量比未使用AI的对照组提高了40%以上。这项研究由波士顿咨询集团(BCG)进行,参与研究的对象主要是一些典型的咨询师和智力工作者。特别是对于那些基础能力较差的人来说,使用AI后的改善幅度更大。研究结果显示,在AI的帮助下,他们的增长幅度达到了43%,而相对而言技能较好的人只有17%的改善幅度。
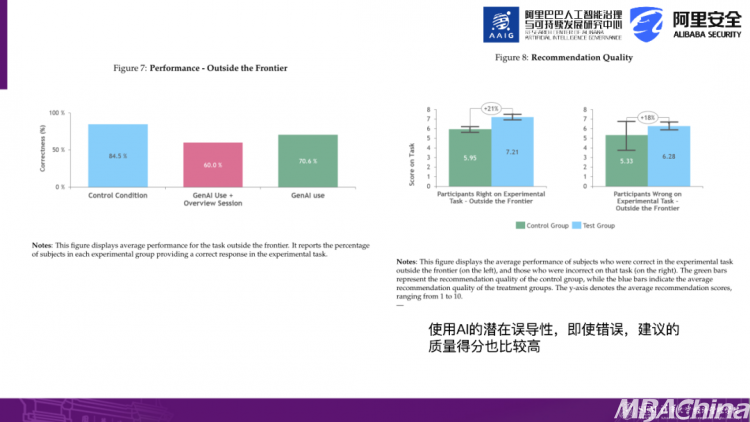
然而,研究还发现了AI的潜在误导性。在超出AI能力范围或边界范围的任务中,使用AI正确率相比于控制组更低,即AI更容易给出不正确的答案。
另一个有趣的发现是,即使AI给出了一个不正确的答案,它仍然会提供一个推荐意见。例如,当我选择A作为答案,而正确答案是B时,AI会告诉我选择A的原因,然后我会对这个原因进行评分。研究发现,这些推荐理由得到了更高的评分,同时也反映了AI的误导性更强。它以一种一本正经的方式给出了错误的答案,但同时告诉你看上去它的推荐是有道理的。这可能导致人们相信了它的结论。
因此,这也指出了一个潜在的问题。对于创意性的事物来说,这可能并不重要,你可以给出一些奇思妙想的想法。然而,对于一些有明确答案的任务,即基于数据分析什么是正确的和错误,比如,如果一个员工使用生成式AI算出一个错误的答案,并且还有一个很自洽的逻辑,那么你更容易被他说服。
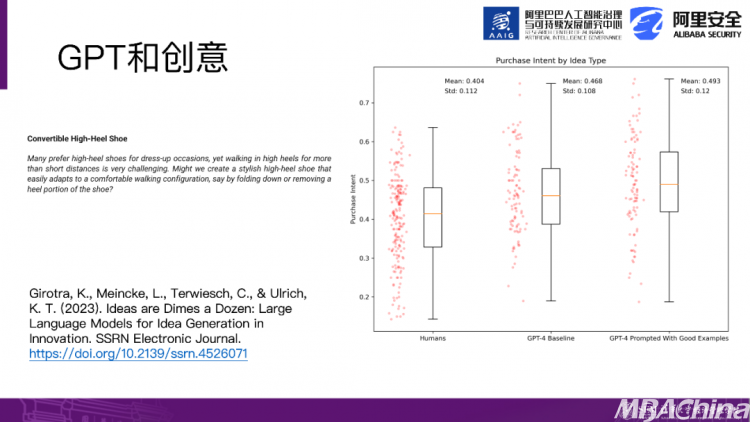
另外一项研究比较了使用Chat GPT生成的创意和一些顶尖大学学生产生的创意。这些顶尖大学包括滨州大学等等。举个例子,有些女士穿高跟鞋会感到不舒服,对此,让这些学生提供一个创意解决方案,他们提出了高跟鞋可以变形的创意。研究对比了学生组和Chat GPT产生的创意,发现Chat GPT产生的创意更具创新性,因此在这个方面它已经超越了人类。


我们的团队目前也在进行大量的人与AI互动的研究。我们实验设计:让人们与AI进行互动,将AI作为他们的个人助手来完成一系列任务。我们的第一个研究设计了四个任务,旨在尽可能多元化地反映职场和不同行业需要人类智力创作的任务。
其中,第一个任务是简历撰写,我们参考了之前在《科学》杂志上发表的任务。第二个任务是创意生成,要求提出某种产品的吸引人的名称,并解释其与未来市场营销的逻辑准备。对于许多产品经理而言,他们需要为产品想出一个有吸引力的名称,并对其市场营销做出合理解释。
第三个任务是解决团队成员之间的人际冲突。设想你是团队的一员,需要提出解决这个冲突的方案。这个任务更加强调创意性。如果你是一个领导者,你的团队成员之间出现了矛盾,你需要提出解决方案。在这种情况下,我们想知道Chat GPT与人类合作时,能否提出更好的解决方案?第四个任务是一个更加复杂的任务。举个例子,要求参与者设计一个现代大学,假设你要引入一个通用型人工智能面向非计算机专业的学生,通识课程需要针对所有人开设。那么这门课程的大纲应该是什么样的?需要涵盖哪些内容?这四个任务都要求人与AI合作完成,我们会评估他们提交的任务成果。
现在让我们来看一下我们的实验设计。首先,我们进行了招募,招募完成后,我们采用了随机分组的方式。将他们随机分成了三个组,分别是HAHA、AHAH和AAAA。然后,将这个任务分成了两种情况。H代表参与者在完成任务时是独立完成的,A代表他们是与AI一起完成的。所以第一组的完成顺序是:先独立完成,然后切换到与AI合作完成,再独立完成,最后再切换回与AI合作,这样就完成了一组任务。而他们使用的工具是基于Chat GPT3.5。第二组是AHAH3.5组,接着还有一个4.0组,他们使用的是更先进的AI工具。所有的四个任务都由AI来完成。

这是我们的整体设计。如上图,无论是针对哪个任务,都会有控制组即不使用AI,以及弱AI组(3.5版本)和强AI组(4.0版本)的存在。对于每个任务,我们都创建了相应的实验情境。因此,针对每个任务,我们可以比较在使用AI和不使用AI时的结果差异。
这是我们的研究结果。如何建立评估成果质量的标准?例如,每个参与者都提交了任务文档,我们需要对这些文档进行评估。为此,我们选择了六位评委来评估每份任务文档,并取平均得出评分。我们将评估结果分为三个维度。首先是整体质量,即这份任务文档的整体得分如何,然后我们将其分为两个子维度。第一个是创新度,即这份方案的创新性如何,是否提出了一些新的想法。第二个是实用性,因为有些想法可能很创新,但却不实用。因此,我们从创新性、实用性和整体质量这三个维度进行评估。

让我们来看一下右边的图表,它表示了总体质量的评分。可以看出,针对不同任务的评价标准,结果差异并不大。现在让我们来看大图,上面列出了任务一、任务二、任务三和任务四。这是一个相对比较的图表,中间小方块的横线代表均值,长尾代表差异。每个组都有好的和差的情况,所以我们需要关注平均值。
从平均值的角度来看,我们可以得出一个结论,即3.5和4.0组明显高于人类组。然而,需要注意的是,4.0组并没有显著高于3.5组。这回答了之前提出的问题,即技术对于AI人机互动的影响是什么。根据这种情况来看,技术对于AI人机互动的影响是微弱的。这再次回到了我最初提出的问题,即在没有进行任何培训的情况下,仅仅提供先进的工具和技术,并没有显著提升,相较于弱AI组的差异则显著。因此,从结果来看,创新度和实用性对于任务的结果是一致的。
有些人可能会担心是否会引发所谓的天花板效应,即3.5组已经很不错了,所以得分很高。然而,实际上我们的评分是在1到10之间,远未达到天花板的水平。平均分也只在7左右或稍微高一些,并没有达到类似9点多的天花板水平。因此,强AI和弱AI之间没有太大差别。这确实反映出一个事实:我们不能单纯追求技术,而是应该关注使用这个工具的人,如何培训和引导他们合理地使用这个工具,这非常关键。

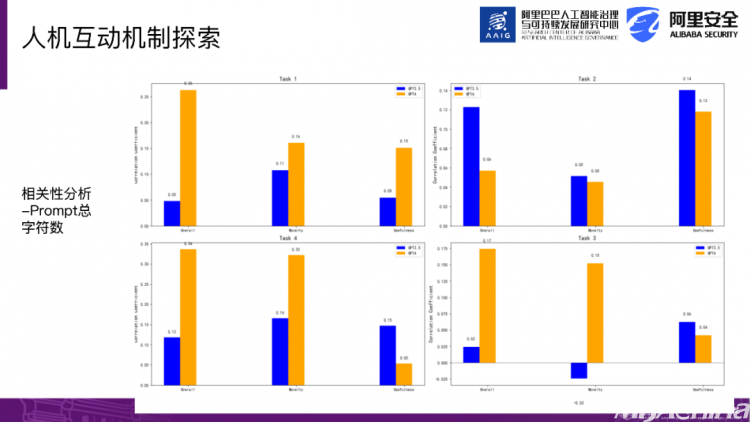
接下来,我们进一步探索了人与AI互动的机制。我们可以看到,即使在使用AI的情况下,不同的人之间差异很大。有些人得分低于三分,而有些人接近满分。那么,是什么造成了这种差异呢?很多人关心的问题是,有些人能很好地使用AI,而有些人却不擅长。
那么,在使用AI时,它的提示词有什么特征呢?因此,我们的研究重点就是探究提示词的特征。我们首先研究了一个比较基础的指标,即提示词的长度。如果提示词太短,那么AI给出的结果肯定不够理想。例如,有些人要求写一篇论文,但并没有提供具体要求,或者要求写一份请假申请,却没有说明理由,这样的效果肯定不好。因此,提示词的长度对于最终评分的质量有一定影响,但影响程度中等,并不是完全取决于提示词的长度。

基于这个发现,我们进一步提出了一些新的机制。我们采用了不同的方法,包括自然语言处理(NLP)的传统方法和最新的NLP方法,提出了许多指标,例如问题词语的多样性和prompt的相似度等等。然而,我们发现这些方法并没有取得最佳效果,所以我们决定用Chat GPT提供定义并进行评分。因此,从这个角度来看,大语言模型似乎对许多自然语言处理方法进行了降维打击。其中2种评分是:发散式评分和是收敛式评分。
发散式评分是指给被评价者一个提示词(发散的),并且搜索范围逐渐扩大。例如,让他提出10个新的想法,这是一个发散式过程。根据他提供的想法,再要求他再提供10个新的想法,这就是一个连续的发散过程。它会吸收更多元的信息。
收敛式评分是越来越集中的观点。从10个想法中挑选出一个重点,并基于这个重点深入、明确地提问。基于这发散和收敛两类机制,我们提出了不同的评分标准,例如问题的明确性和深度。
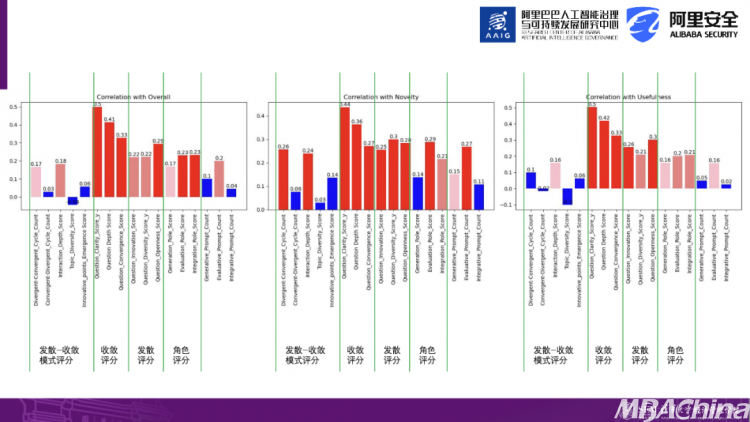
让我们来看一下结果,简单相关分析表明,在提示词得分这个维度上与后续作品结果的评分之间存在影响。可以看出,收敛和发散这两个维度确实影响着后续成果的质量。这实际上反映了与AI互动时的系统工程特性。你需要学会如何提问,并需要有系统化的提问方式,才能获得更好的效果。其中最明显的指标之一就是问题的清晰度,也就是问题的明确性。

我们还研究了另外一个评价因素,称为差异性分析。实际上,这反映了AI的出现是否会引发新的公平或不公平现象。它可能放大人之间的能力差异,但也可能缩小人之间的差异。
之前我们分享的一篇文章提出了AI降低人与人之间能力差异的观点,使那些能力较弱的人也能够实现相似的成绩。我们发现,强AI确实具有这样的效果。尽管从绝对值来看,4.0和3.5差别不大,但4.0的方差更小。使用更好的工具可以使每个人的水平相当于提高了人的下限。在方差方面,可以看到在三个组中,4.0的方差最小,并且明显低于人这组的方差。
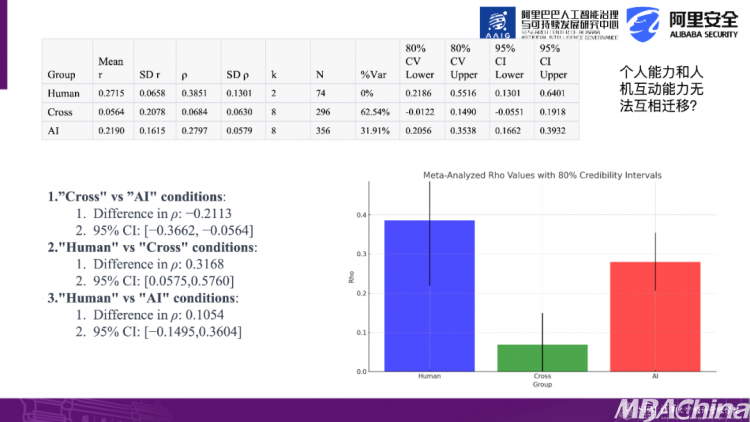
接下来,让我们来看一个非常有趣的现象。之前提到的《Science》文章的逻辑是,如果一个人的能力强,在没有借助AI工具的情况下,能力强的人会表现出持续的能力。就像考试一样,如果我一次考试成绩好,那么下次考试也会好,再下次考试也会好。而那些考试成绩不好的人,一次考试不好,下次考试也不好。如果我们观察一个人群,会发现前后得分之间的相关性会比较高。得分高的人下次仍然得分高,得分低的人下次仍然得分低,这表明前后之间存在较高的相关性。
这种相关性反映了人这一组的情况。我们观察第三列,得分为0.3851,因为他们完成了4个任务,我们观察第一个任务和第三个任务之间,在没有借助AI的情况下,我们可以发现这种能力存在持续性。这是人这一组的情况。接下来,让我们观察AI这一组。例如,第一个任务使用了AI,第二个任务也使用了AI,第三个任务也使用了AI。然后我们对这些任务之间的相关性进行了分析,可以看到它们之间的相关度为0.28,也呈现出一定的一致性或持续性。
但有趣的是,在人与AI工具之间切换时,没有这种持续性。这说明了什么呢?个人的能在不借助AI的情况下和使用AI的情况下,它们之间的能力不具备迁移性。尽管数据量不是很大,但我们初步发现它们之间不具备迁移性。因此,这涉及到能力的重新洗牌,也涉及到企业在引入大量AI后对于招聘模型或素质模型的重新调整。即以前你所看重的一些能力,在新的形势下变得不再重要。
举个例子,以前我们招聘时很注重Excel的能力,因为它对提升效率非常重要。但现在有了Chat GPT,它的能力远远超过了Excel,所以即使我不会用Excel,但我熟练运用code interpreter,这在数据分析方面就成为一项非常重要的能力。
再举个例子,有些人写公文写得非常好,但他却没有很好的思想能力,这也是一种能力。在新的形势下,写作能力并不重要,因为Chat GPT写出来的公文非常标准,无论需要什么样的风格,它都能做到,所以思想能力变得突出,因为它能告诉我们写什么内容,逻辑框架是什么。所以这涉及到能力的重新洗牌。

我们初步得出的结论如下:1、AI确实能提升任务的整体质量、创新性和实用性。
2、AI未必会降低人们之间的差异,反而可能引发新的形势下的不平等或差异,只是将原有的一些优势抹平,同时也会引入一些新的因素。
3、目前来看,AI的能力对结果的影响并不明显,GPT3.5和GPT4.0影响不明显,但我们知道4.0在各项评测指标上明显优于3.5。因此,这就显示出人不一定能充分发挥AI的能力,这牵涉到一个根本问题,即技术投入和人力投入。
4、人与AI的互动过程对结果有显著影响。

这也引出了一些其他的思考,例如为什么有些人觉得他们的Chat GPT或生成式AI比较笨,而有些人的作品又神奇又高质量。这反映了一种新的能力,不同于过去我们讨论的智商、情商、领导力、团队协作力等等,现在是否还需要考虑AI能力、技术协作能力这样的因素?实际上,在国外的一些讨论中,是否具备与AI合作的能力在未来的职场或筛选过程中被视为一个重要的衡量标准。
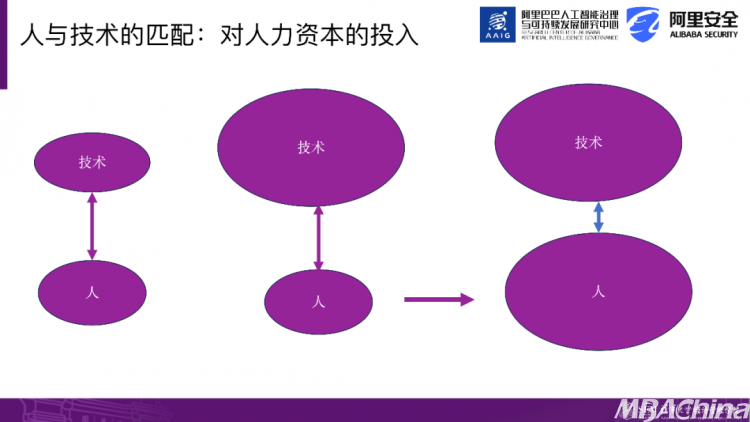
因此,我们已经提到过,尽管技术的发展很迅猛,但我们也必须跟上对人才的培养,确保人与AI、人与技术的匹配是非常重要的。

因此,我们的第二项研究集中在如何提升与AI合作的能力上。我们还编制了一套培训教材《高效人机互动:生成式AI中的提示词与交互策略指南》。
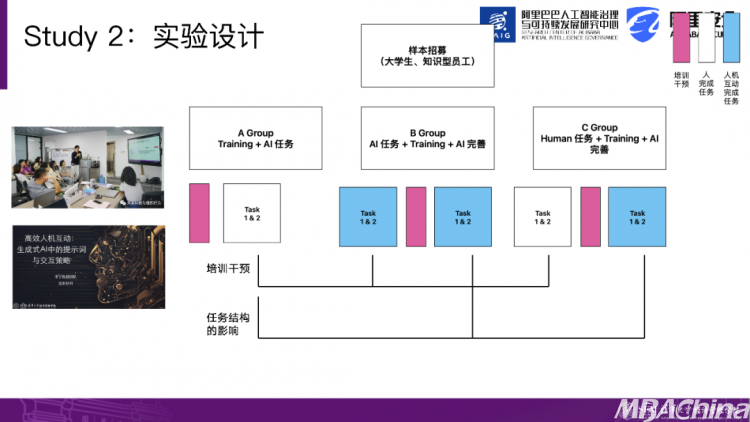
这涉及到我们的第二项研究,我们开始进行了样本招募,并将其分为三组,唯一的区别是加入了培训环节。我们思考的问题是,如果加入培训环节,教人们如何与AI进行互动,这涉及到不同的假设。
当我们对人进行投资时,3.5版本的AI是否能超过4.0版本的AI呢?如果我使用了一个较弱的3.5版本AI,然后接受了这样的培训,我可能会达到比使用4.0版本AI效果更好的结果。如果再加入培训环节,会放大人的差异还是缩小人的差异?
比如在使用AI时,本身就存在差异,但如果我们提供了这样的培训,它有可能缩小这种差异,但也有可能放大差异。因为培训本身是一个学习过程,每个人的学习能力都不同,这可能会放大人的差异。我们的第二个实验设计也较为复杂。在每个组中,我们随机分配了3.5版本和4.0版本的AI,同样也设计了一个强弱AI对比的实验设计,并将其分为三组。粉色的线代表培训的投入和干预。
在A组中,我们在培训完成后让他们完成两个更复杂的任务。而B组则是在开始不给他们培训,让他们在自然条件下完成这两个任务,然后进行培训,培训后让他们运用培训结果来改进之前使用AI生成的任务。第三组的设计也非常有意思。一开始,我们不让他们接触任何工具,完全依靠人与人之间的合作来完成任务,然后在培训后,让他们运用AI的知识来改进他们自己生成的任务。
那么这样做有什么好处呢?我们可以单独观察这三种情境下的培训后使用AI、单纯使用AI以及人与人独立完成任务的差异和绩效。我们还可以进一步观察第二个问题,有意识地控制结构的问题。比如,在培训后直接使用AI,先使用AI,然后对AI生成的结果进行优化;还是不依赖AI工具,先凭借自身能力完成任务。
这时候,我再引出AI的供给,实际上涉及到工作流程的设计。哪种设计方式能够最大化地提升结果,对于工作设计来说具有启示。我们可以开始时人与AI紧密配合,还是先由人来完成任务,然后再引入AI。从理论上来说,如果人先完成任务,可以充分调动大脑的知识储备。然后,当AI介入时,它给人带来不同的启示,进行优化。有可能说当人和AI并行处理任务时,能够最大程度地激发创新的想法。这个答案目前还不清楚,因为数据还没有完全分析完毕。
后续计划:第一个研究方向是,目前所有的研究,包括国际上许多团队的研究,都是单个人与单个AI节点的互动,人与AI的互动。但实际上,要考虑到真实的组织,人是在一个网络中。所以,需要将单点的互动转移到多节点的互动上。比如市场团队或者软件工程师开发团队,在这样的团队中,引入了一个AI节点,它对工作效率的提升,包括人与人之间的节点连接,还设计了在一个团队中,单节点AI和多节点AI之间可能存在的差异。
如果将视角扩大到组织层面,AI不再仅仅是辅助人类完成任务,而是成为一个多节点,在组织中与人类节点共同存在的组织体系。
后续我们需要在企业中考察其长期影响。涉及到例如对知识型零工绩效的影响,以及AI对企业效率和创新的影响,这些在真实环境中进行的结果。实际上,现在很多企业都在思考一个问题,即如何提高效率,如何实现更好的创新。当将AI作为一种工具引入企业时,它对企业的结果会有何影响?

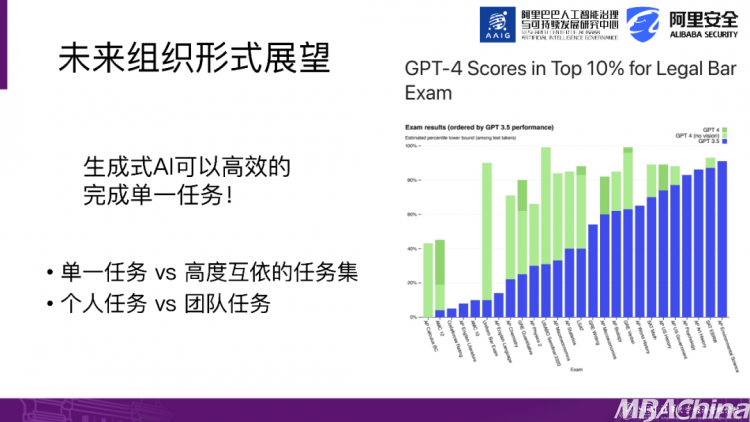
接下来,让我们展望一下未来组织形式。例如,我们刚才提到生成式AI可以高效地完成单一节点的任务。但是,我们的很多任务并不仅仅考虑单一任务,而是一个任务集。我们每个人的任务可以进一步分解,实际上是一个多节点任务集,其中一些涉及与人的沟通,甚至是物理流转。在这种情况下,AI对我们的影响是什么呢?

举一个例子来说明,这也是麦肯锡报告中提到的一个例子。以软件工程师为例,他的任务可以分为编写代码、修正、研发、与数据库连接以及与其他技术人员沟通等。我们可以将每个任务设计为一个节点,在引入AI之后,一些节点会变得缩小。例如,在编写初始代码时,这部分工作就变得不那么重要了,节省了时间。但是,一些节点则会放大比如人与人之间的沟通,如何整合我们与AI的互动,形成一个互动网络。甚至可能引出一些以前不存在的任务,例如确保信息的准确性等等。
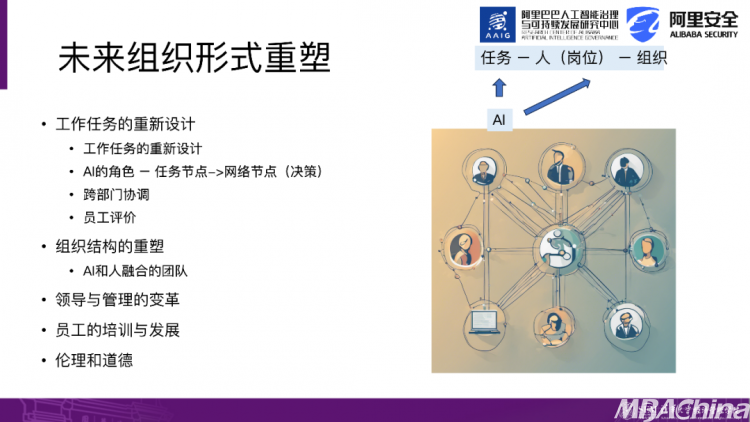
总结一下,过去,我们关注的是AI对任务的支撑,接下来关注的是AI对组织的支撑。AI并不仅仅是帮助员工完成某个任务,而是扮演了一个角色转变,从单一任务节点变成了一个网络节点,即决策角色。例如,在企业中一个典型的问题是跨部门协调和跨部门资源整合的问题。在整合这一切的过程中,究竟是谁来担当这个角色呢?实际上,各个部门都有自身的利益。除了在完成任务方面,AI还有可能成为一个决策者和整合者。
因此,如果我们将视角扩大,我的另一个研究方向就是组织网络。过去的组织网络仅仅是由人构成,人与人之间的连接形成了沟通和信息交流的网络。但是,如果我们不断将AI引入到组织中,就像图表所展示的那样,在未来的网络中,涉及到人与AI之间的互动,以及AI与AI之间的互动,需要考虑技术层面的因素。
对于跨部门的协调,甚至员工评估等问题。举个例子,就像在我们的实验任务中,我们每个任务的文档都由6个人进行评估,然后得出一个分数。我们还进行了另一个实验,让GPT来进行评估,而GPT的评估结果与人的评估结果高度相似。这反映了使用GPT进行评估相比于单纯由个人进行评估的结果更好,准确度误差更小。
这就相当于将6个人的评估结果合并,才能与GPT的评估结果媲美。过去,我们常说评估需要有一个黄金标准,用来判断好坏,需要有一个标准。过去的黄金标准就是要多个专家进行评分,一个专家的评分并不能作为标准,需要找到10个专家,他们的评分才能作为黄金标准。
在我们的研究中,也是不断增加评价人的数量。大家可能发现,当GPT评价次数也增加了,但是这并没有改变评分的分布,相反,人的评分分布越来越修正。从这个角度来看,可能GPT第一次评价的人是黄金标准,而其他人的评分存在较大误差,只有通过增加不同的评估者,才能接近黄金标准。
此外,还有一些关于组织结构的问题,即如何重塑人与AI的融合,包括领导和管理的启示。在引入AI之后,领导的职责也会发生变化,涉及员工培训与发展的问题,在组织中进行培训和发展非常关键,关键是培训哪些内容。
在引入AI后,会对这些课程进行重组,重新洗牌能力,还包括道德伦理和员工接受程度的问题。实际上,我们发现现在AI非常热门,但是大多数企业对于AI的使用普及度还非常低。这涉及到员工对AI的接受程度,以及他们对与自己工作相关的感知。实际上,还有很长的路要走。
嘉宾简介

李 宁
现任清华大学经济管理学院领导力与组织管理系Flextronics 讲席教授、系主任。研究兴趣主要包括组织协作、团队网路和效能、个体和团队创新机制研究、领导力、大数据在组织管理中的应用以及中国管理概念研究。近年来的研究从跨学科融合的视角,结合数据科学(大数据、机器学习、人工智能)和人力资源管理及组织行为科学来研究员工、领导、团队及组织的行为模式和效能,重点对组织能力、跨部门协同、创新能力和知识员工效能等课题进行了深入研究。
(本文转载自清华MBA ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。
热门推荐


备考交流
最新动态
- 清华大学经济管理学院建院40周年庆祝大会举行 2024-04-29
- 白重恩:致敬、传承、创新、展望丨建院40周年庆祝大会院长致辞 2024-04-29
- 全国工商管理专业学位研究生教育指导委员会成立三十周年座谈会在清华大学顺利召开 2024-04-25
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 05/04 报名 | “中国经济变局下的企业风险管理”复旦大学李若山教授公开课暨联合宣讲会
- 05/08 集赞赢取精美礼品 | 面试诀窍、备考经历、海外交换,报名5月8日面试圆桌派,用10个问题揭秘三位高分学长的备考秘籍!
- 05/12 招生工作|浙工大校园开放日暨MBA、MEM项目宣讲会通知
- 05/12 「复旦大学 EMBA 项目」与「复旦-台大 EMBA 项目」介绍会 | 活动预告
- 05/17 限时抢位!长江商学院MBA项目5月北京体验课
- 05/18 5月18日 | 全国首场中国商学院招生巡展暨2025招生政策发布会(北京站)重磅来袭!
- 05/18 5月18日 | 北京体育大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 中国矿业大学(北京)邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 北京师范大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
- 05/18 5月18日 | 天津大学邀您参加中国商学院招生巡展暨2025招生政策发布会(北京站)
热门资讯
MBA院校号
-
最新动态:
MPAcc(非全)、MBA调剂公告 -
最新动态:
论坛预告 | 2024内部审计高质量发展论坛










